
Want to harness the power of Alibaba Cloud’s Qwen AI models directly on your own hardware? This comprehensive guide provides a step-by-step walkthrough for downloading, installing, and running various Qwen AI models – including the latest Qwen 3 series and the versatile Qwen 2.5 family (Coder, Max, VL, etc.) – locally on your Windows, macOS, or Linux computer using the popular Ollama software. Enjoy enhanced privacy, offline access, and full control over your AI experimentation.
Whether you’re a developer, researcher, or AI enthusiast, follow these simple steps to get started with Qwen AI on your local machine in minutes.

Table of Contents
- What is Ollama and Why Use It for Qwen?
- Step 1: Obtain the Ollama Software
- Step 2: Install Ollama on Your System
- Step 3: Verify Ollama Installation
- Step 4: Download Your Chosen Qwen AI Model(s)
- Quick Reference: Qwen Model Ollama Commands & VRAM
- Step 5: Run Your Qwen AI Model Locally
- Step 6: Test Your Qwen AI Installation
- Troubleshooting Common Issues
- Other Local Deployment Options (Advanced)
What is Ollama and Why Use It for Qwen?
Ollama is a powerful and user-friendly tool that streamlines the process of downloading, setting up, and running large language models (LLMs) locally. For Qwen AI models, Ollama offers several advantages:
- Simplicity: Run complex models with single-line commands.
- Cross-Platform: Works seamlessly on Windows, macOS, and Linux.
- Model Management: Easily download and switch between different Qwen models and versions.
- Community Support: A large and active community for troubleshooting and sharing tips.
- Quantization: Ollama often provides access to quantized versions of models, which require significantly less VRAM and disk space while retaining much of the original performance.
Using Ollama is currently one of the easiest ways to get started with Qwen AI models on your personal computer.
Step 1: Obtain the Ollama Software
Before you can use any of the Qwen AI models locally, you must first install Ollama. This software provides the necessary environment to download and interact with the models.
- Download Installer: Click the button below to navigate to the official Ollama download page and get the installer compatible with your operating system.
Step 2: Install Ollama on Your System
Once you’ve downloaded the Ollama installer for your operating system (e.g., `OllamaSetup.exe` for Windows):
- Run Setup: Locate the downloaded file and double-click it (or run it according to your OS instructions) to begin the installation.
- Follow the Prompts: Complete the setup by following all on-screen instructions. This process is usually quick and straightforward.
This ensures you have the right environment ready for any Qwen AI model.
Step 3: Verify Ollama Installation
After installation, confirm that Ollama is properly set up on your system:
- Windows Users: Open Command Prompt (search for “cmd”) or PowerShell from the Start menu.
- macOS/Linux Users: Open your Terminal application.
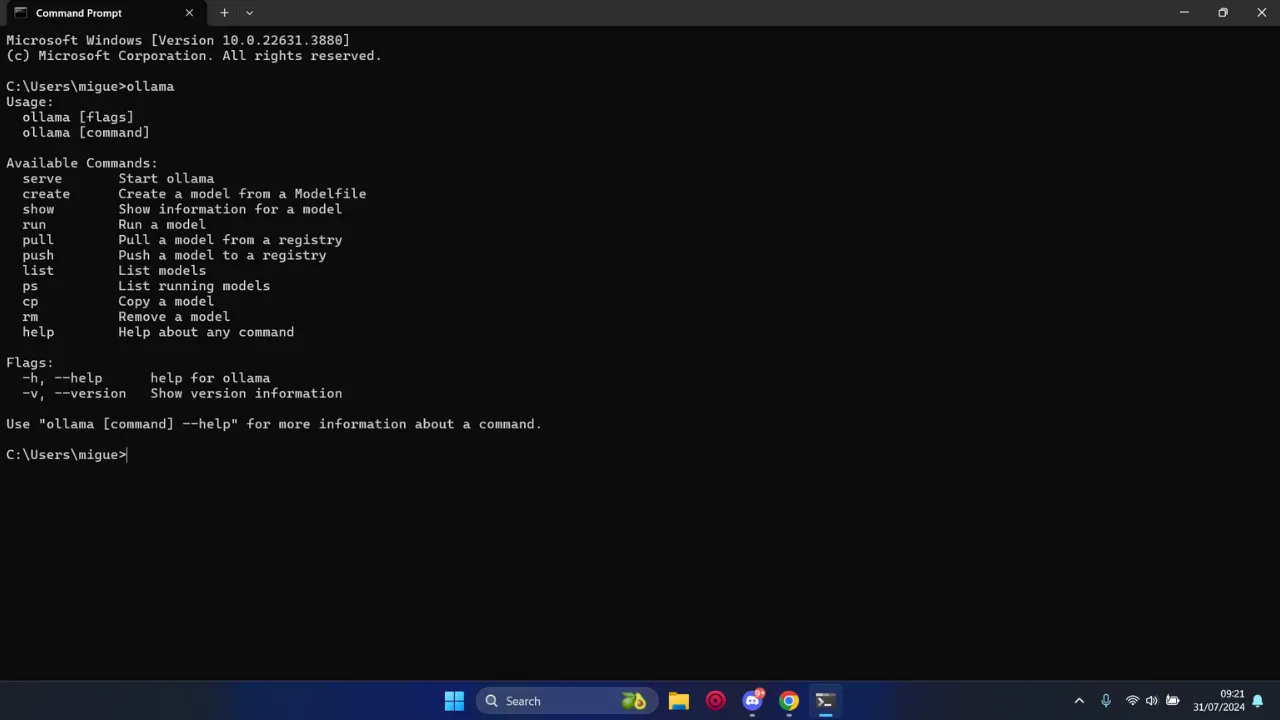
- Check Installation: In the terminal/command prompt, type
ollamaand press Enter. If Ollama is installed correctly, you should see a list of available Ollama commands and usage information. If you see an error like “command not found,” try restarting your terminal or your computer.
Successfully completing this step means you’re ready to download and run Qwen AI models.
Step 4: Download Your Chosen Qwen AI Model(s)
With Ollama installed, you can now download various Qwen AI models. Qwen offers a wide range of models from different series (like Qwen 3 and Qwen 2.5) and sizes (from 0.5B parameters up to very large MoE models). Smaller models and quantized versions require less VRAM and download faster.
To download a model, you’ll use the ollama run [model_tag] command. The first time you run this for a specific model, Ollama will download it. Here are some examples for popular Qwen models (always check the Ollama Library for the latest available Qwen model tags and quantized versions like q4_K_M for better performance on limited hardware):
Example Qwen 3 Models:
ollama run qwen2:0.5bollama run qwen2:1.5bollama run qwen2:7b(Note: Qwen 3 models might use specific tags like qwen3:8b-q4_K_M or similar. The exact tag for Qwen 3 models on Ollama should be verified from Ollama’s official library as they are continuously updated. The examples above use qwen2 as a placeholder if specific qwen3 tags for smaller models aren’t immediately available or aliased under qwen2. For the newest models, always refer to Ollama’s site.)
Example Qwen 2.5 Models:
ollama run qwen:0.5bollama run qwen:4bollama run qwen:7bollama run qwen:14bollama run qwen:32bollama run qwen:72bSpecialized Qwen Models (Examples):
For specialized models like Qwen 2.5 Coder, you might find tags such as:
ollama run qwen-coder:7bImportant:
- Make sure you have a stable internet connection. Downloads can be several gigabytes.
- For models with different quantization levels (e.g.,
-q4_K_M,-q5_K_M), choose one that balances performance with your VRAM. Using a tag without a specific quantization (e.g.,ollama run qwen2:7b) will usually download a default, often well-optimized, version. - The process may take longer for larger models. Ollama will show download progress.
Quick Reference: Qwen Model Ollama Commands & VRAM
Below is an illustrative table. **Always verify the exact model tags and VRAM estimates from the official Ollama library and your chosen Qwen model’s documentation, as these can change.** Quantized models (e.g., Q4_K_M) will require significantly less VRAM than their full-precision counterparts.
| Qwen Model Series & Size | Example Ollama Tag (Check Library!) | Est. VRAM (Quantized) | Focus / Link to Guide |
|---|---|---|---|
| Qwen3 0.6B / 1.7B | qwen2:0.5b / qwen2:1.5b (Verify exact Qwen3 tags) | ~2-4 GB | Qwen 3 Series |
| Qwen3 4B / 8B | qwen2:7b (Verify exact Qwen3 tags like qwen3:8b-q4_K_M) | ~4-8 GB | Qwen 3 Series |
| Qwen3 30B-MoE | qwen3:30b-a3b-q4_K_M (Example) | ~20-24 GB | Qwen 3 Series |
| Qwen2.5 0.5B / 1.5B / 3B | qwen:0.5b / qwen:1.5b / qwen:3b | ~2-6 GB | Qwen 2.5 Family |
| Qwen2.5 7B / 14B | qwen:7b / qwen:14b | ~5-10 GB | Qwen 2.5 Family |
| Qwen2.5 32B / 72B | qwen:32b / qwen:72b | ~18-40 GB | Qwen 2.5 Family |
| Qwen 2.5 Coder (e.g., 7B) | qwen-coder:7b (Example) | ~5-8 GB | Qwen 2.5 Coder |
VRAM estimates are approximate for quantized models and depend heavily on the specific quantization level. Larger models may not be feasible on all consumer hardware.
Step 5: Run Your Qwen AI Model Locally
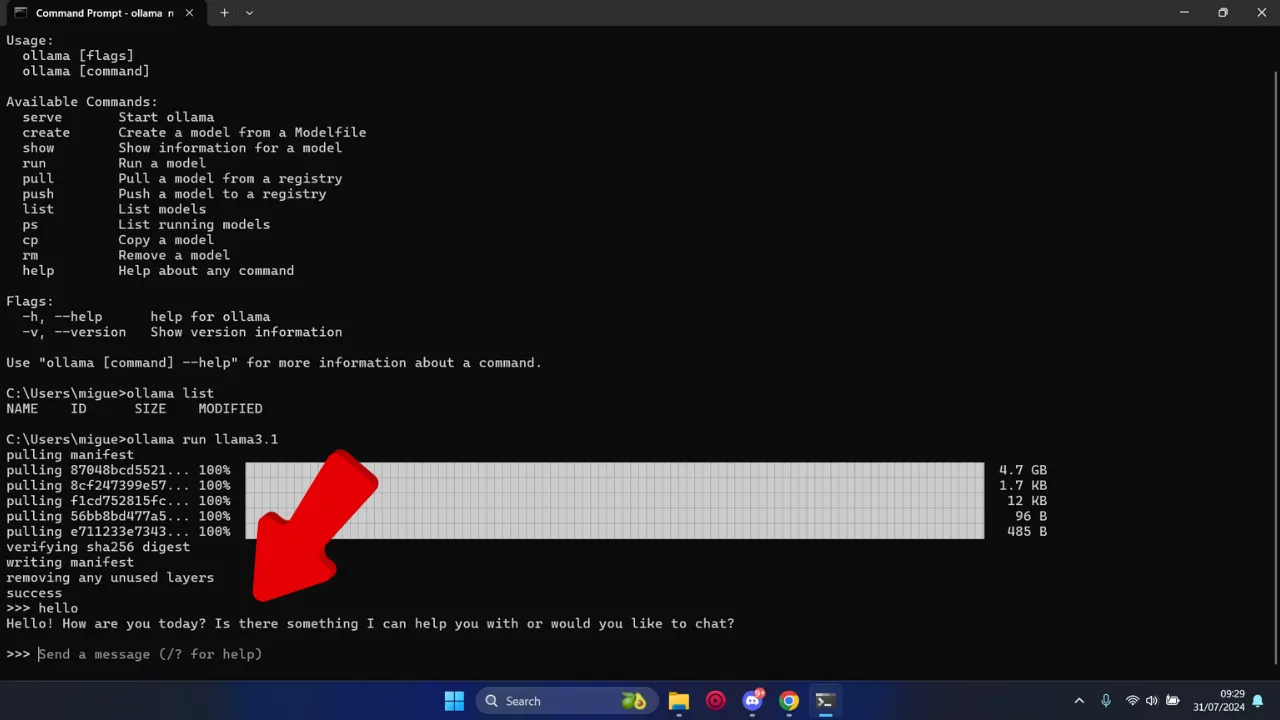
Once the download is complete for your chosen model, running it is simple. If you used ollama run [model_tag] to download, the model will typically start immediately after downloading, and you’ll see a prompt like >>> Send a message:.
If you downloaded a model previously (e.g., with ollama pull [model_tag]) or want to run it again after closing the terminal, just use the same ollama run command:
ollama run qwen2:7bThe model will load into your system’s memory (RAM and/or VRAM if you have a compatible GPU). Larger models may take a few moments to load, so be patient.
Step 6: Test Your Qwen AI Installation
Confirm that your Qwen AI model is functioning correctly:
- Send a Sample Prompt: At the Ollama prompt (
>>>), type a question or instruction and press Enter. For example:>>> What is Qwen AI?Or, for a coding model like Qwen 2.5 Coder:
>>> Write a python function to reverse a string - Assess Response: If you receive a coherent and relevant response, your setup is successful!
- Experiment: Try more complex queries, ask for different text formats, or test its reasoning capabilities depending on the model you’ve loaded. Explore various prompting techniques to get the most out of your model.
- Exit: When you’re done, you can type
/byeto exit the Ollama session for that model.
Troubleshooting Common Issues
- “Command not found” for `ollama`: Ensure Ollama was installed correctly and its path is added to your system’s environment variables. Try restarting your terminal or PC.
- Slow Performance:
- Ensure you have a compatible GPU and that Ollama is configured to use it (often automatic). Running large models on CPU only will be very slow.
- You might be running a model слишком large for your VRAM. Try a smaller model or a more aggressively quantized version (e.g., Q2_K, Q3_K_S if available).
- Close other resource-intensive applications.
- Model Download Issues: Check your internet connection. Ensure you have enough disk space. Try the download again.
- Errors During Model Run: The model might require more VRAM than available. Check the Ollama logs or GitHub issues for model-specific problems.
- Finding Model Tags: Always refer to the Ollama Model Library for the exact, up-to-date tags for Qwen models (e.g.,
qwen2:7b,qwen-coder, etc.) and their available quantizations.
Other Local Deployment Options (Advanced)
While Ollama is excellent for ease of use, developers seeking more control or specific performance optimizations can also run Qwen models locally using other frameworks:
- LM Studio: A popular desktop application with a GUI for running various LLMs, often supporting Qwen models in GGUF format.
- llama.cpp: A C/C++ library for efficient inference, supporting GGUF formats. Requires more technical setup.
- vLLM / SGLang / Text Generation Inference (TGI): For high-throughput serving and more advanced deployment scenarios.
You can typically find Qwen model weights and specific instructions for these frameworks on Hugging Face or the QwenLM GitHub repositories.
By following these steps, you’ll have your chosen Qwen AI model up and running locally, ready to assist with a wide range of tasks. Whether you need quick inference on minimal hardware with a small quantized model or the power of a larger Qwen variant for complex projects, local deployment offers unparalleled control and privacy. Happy experimenting!