Qwen 3
Qwen 3 was the generation that put Alibaba's open-weight models on the map. When it launched in April 2025, AI researcher Nathan Lambert called the lineup "the new open standard" — and he wasn't wrong. Six dense models, two MoE variants, 119 languages, and performance that matched or beat GPT-4-class systems, all under Apache 2.0.
That was six months ago. Qwen 3.5 has since taken the crown, and Qwen 3 is now the previous generation. But "previous" doesn't mean irrelevant. The dense models remain the go-to choice for fine-tuning. The Qwen3-Next hybrid architecture introduced efficiency breakthroughs that directly shaped Qwen 3.5's design. And millions of production deployments still run Qwen 3 today.
This guide covers the full Qwen 3 family — including Qwen3-Next, which most sites completely overlook — and helps you decide whether Qwen 3 still makes sense for your use case or if it's time to move to 3.5.

In This Guide
Qwen3-Next: The Hybrid Architecture That Changed Everything
Bottom line: Qwen3-Next-80B-A3B is the single most efficient model in the entire Qwen 3 family. It matches or beats the 235B flagship on most benchmarks while activating only 3B parameters per token — a staggering 3.75% of its total 80B weights.
Released in September 2025, Qwen3-Next was Alibaba's proof-of-concept for a radically different architecture. Instead of the standard Transformer attention used in every other Qwen 3 model, it combines three mechanisms in a repeating block: GatedDeltaNet (linear attention for speed), GatedAttention (standard attention for precision), and MoE routing (512 experts, 10 active + 1 shared per token).
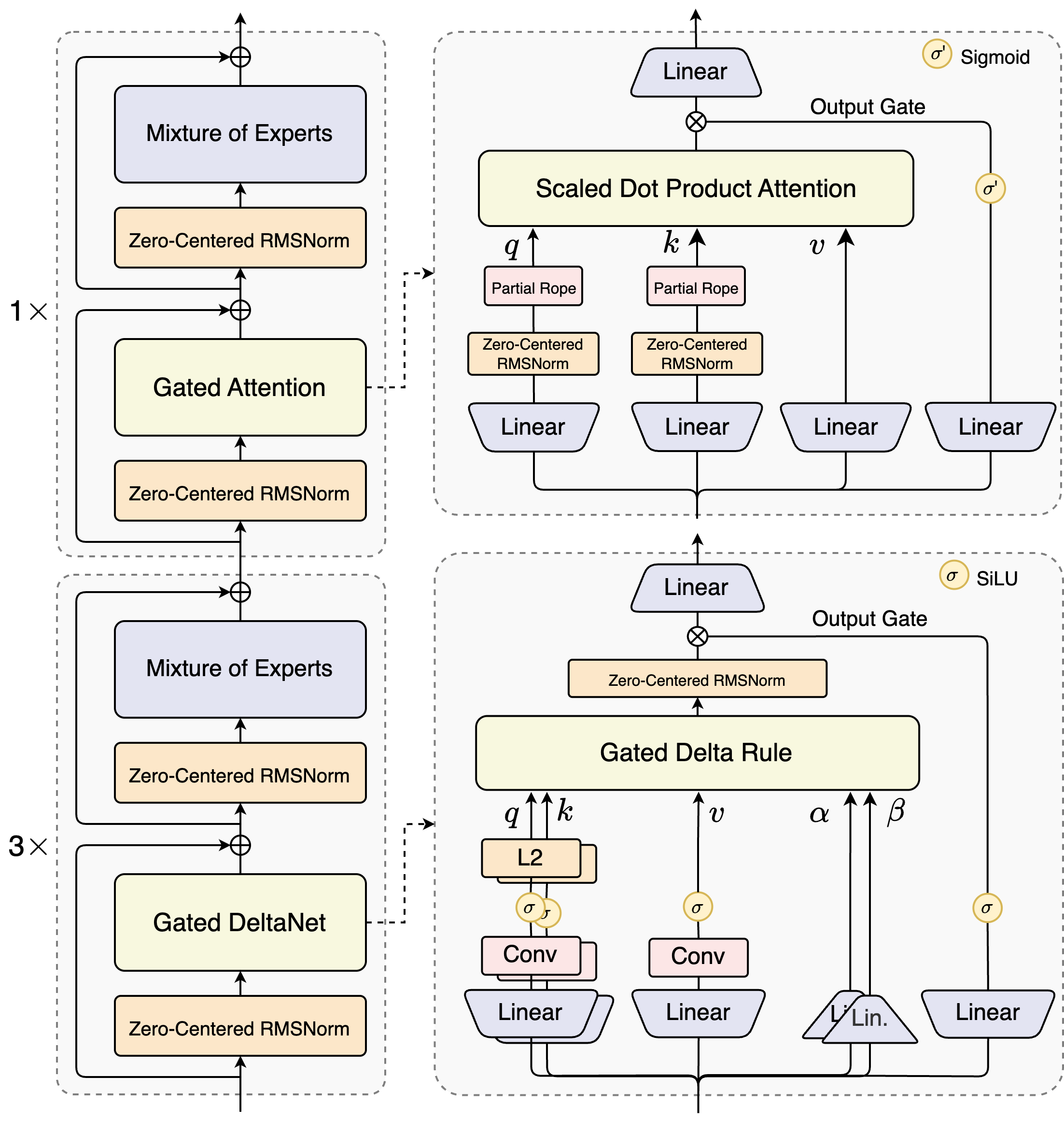
The practical upshot? At sequences longer than 32K tokens, Qwen3-Next delivers 10x the throughput of Qwen3-32B. At around 1 million tokens, it hits 3x the speed of standard attention models. Training costs drop by 90% compared to Qwen3-32B-Base. This isn't incremental — it's a generational leap in efficiency.
Two variants exist: Qwen3-Next-80B-A3B-Instruct (non-thinking, optimized for chat and tool use) and Qwen3-Next-80B-A3B-Thinking (reasoning mode with chain-of-thought). Both support 262K native context, extendable to 1 million tokens via YaRN — and the RULER benchmark confirms this isn't just a marketing number. Qwen3-Next scores 91.8 average accuracy at 1M tokens, nearly matching the 235B flagship's 92.5 and far exceeding Qwen3-30B's 86.8.
Qwen3-Next Instruct Benchmarks vs the Rest of the Family
| Benchmark | Qwen3-Next-80B | Qwen3-235B | Qwen3-32B |
|---|---|---|---|
| LiveBench | 75.8 | 75.4 | 59.8 |
| LiveCodeBench v6 | 56.6 | 51.8 | 29.1 |
| Arena-Hard v2 | 82.7 | 79.2 | 34.1 |
| WritingBench | 87.3 | 85.2 | 75.4 |
| AIME25 | 69.5 | 70.3 | 20.2 |
| MMLU-Pro | 80.6 | 83.0 | 71.9 |
Qwen3-Next wins on live benchmarks (LiveBench, LiveCodeBench, Arena-Hard, WritingBench) while the 235B retains an edge on static knowledge tests (MMLU-Pro, AIME25).
The pattern is clear: Qwen3-Next excels at tasks that reflect real-world usage — live coding, open-ended conversation, creative writing. The 235B still leads on heavily-studied academic benchmarks, which is worth noting when evaluating these numbers. On the reasoning side (Thinking variant), the 235B maintains a wider lead: 92.3 vs 87.8 on AIME25, 74.1 vs 68.7 on LiveCodeBench. If deep mathematical reasoning is your primary need, the 235B remains the stronger pick within the Qwen 3 family.
The Thinking variant tells a slightly different story. On deep reasoning tasks, the 235B still wins:
Qwen3-Next Thinking Mode vs 235B and Gemini
| Benchmark | Qwen3-Next-Think | Qwen3-235B-Think | Gemini 2.5 Flash-Think |
|---|---|---|---|
| AIME25 | 87.8 | 92.3 | 72.0 |
| LiveCodeBench v6 | 68.7 | 74.1 | 61.2 |
| TAU2-Airline | 60.5 | 58.0 | 52.0 |
| TAU1-Retail | 69.6 | 67.8 | 65.2 |
The 235B leads on pure math and coding reasoning, but Qwen3-Next wins on real-world agentic tasks (TAU benchmarks). Both crush Gemini 2.5 Flash.
This split matters for choosing between the two. If you're building agents that interact with real-world systems — booking flights, handling customer service workflows, managing retail operations — Qwen3-Next's TAU benchmark leads suggest it handles structured, multi-step tasks better than even the 235B. For math competitions and complex coding challenges, the 235B remains king within the Qwen 3 family.
Community adoption has been strong. HuggingFace hosts 79 quantized versions and 34 fine-tunes of Qwen3-Next. You can run it today on Ollama, LMStudio, or serve it via AWS Bedrock, NVIDIA NIM, and Together AI. For a model that was positioned as a research preview, that's a remarkably mature ecosystem.
The Original Lineup: Dense and MoE Models
The April 2025 launch gave us six dense models (0.6B through 32B) and two MoE variants (30B-A3B and 235B-A22B). All share the same tokenizer, chat template, and hybrid thinking/non-thinking capability. Swap sizes without touching your code.
The dense models are where Qwen 3 still holds a genuine advantage over Qwen 3.5. If you're fine-tuning — which most production teams are — a dense 8B or 32B model is simpler to work with, easier to quantize predictably, and has a more mature LoRA ecosystem than any MoE variant. The 32B dense model remains one of the best creative writing models in the open-weight space, a fact the community consistently confirms on r/LocalLLaMA.
Quick Reference: All Qwen 3 Base Models
| Model | Type | Total / Active | Context | Min VRAM (Q4) | Best For |
|---|---|---|---|---|---|
| Qwen3-0.6B | Dense | 0.6B | 32K | ~2 GB | Edge, IoT, Raspberry Pi |
| Qwen3-1.7B | Dense | 1.7B | 32K | ~3 GB | Mobile, quick prototypes |
| Qwen3-4B | Dense | 4B | 32K / 128K | ~4 GB | Local dev, lightweight agents |
| Qwen3-8B | Dense | 8.2B | 32K / 128K | ~6 GB | Best balance of speed + quality |
| Qwen3-14B | Dense | 14B | 32K / 128K | ~10 GB | Strong all-rounder |
| Qwen3-32B | Dense | 32.8B | 32K / 128K | ~20 GB | Creative writing, fine-tuning |
| Qwen3-30B-A3B | MoE | 30.5B / ~3.3B | 32K / 128K | ~20 GB | Fast inference, 90%+ of flagship |
| Qwen3-235B-A22B | MoE | 235B / ~22B | 32K / 128K | ~80 GB | Open-source flagship |
Our pick for most users: the Qwen3-8B strikes the best balance between quality and accessibility. It runs under 10 GB VRAM with Q4 quantization, handles multilingual tasks well, and has the deepest community support. If you have a 24 GB GPU (RTX 4090, A5000), jump to the 32B or 30B-A3B — the quality gap is significant, and you can check exact compatibility here.
The 2507 Update: Dedicated Thinking and Instruct Variants
In July 2025, the Qwen team made a philosophical shift. Instead of one hybrid model that switches between thinking and non-thinking modes via a parameter, they released dedicated variants — each independently optimized for its mode.
The results were dramatic. The 235B-Instruct-2507 jumped from 24.7 to 70.3 on AIME25 in non-thinking mode — that's not a typo. ZebraLogic went from 37.7 to 95.0. Context windows expanded from 32K native to 256K native with up to 1 million tokens via DCA + MInference sparse attention.
Three model sizes received the 2507 treatment: 4B, 30B-A3B, and 235B-A22B. Each comes in both Instruct and Thinking flavors. If a 2507 variant exists for the size you want, always use it over the original April release — the performance gap is too large to ignore. For the 0.6B, 1.7B, 8B, 14B, and 32B dense models, the original April versions remain the latest available.
One standout: the 4B-Thinking-2507 hits 81.3 on AIME25, rivaling the much larger Qwen2.5-72B-Instruct. That kind of reasoning density in a 4B model is genuinely remarkable — and useful if you're deploying on constrained hardware but need strong math capabilities.
Qwen 3 vs Qwen 3.5: Which Generation Should You Use?
This is the question everyone's asking, so here's the honest answer: for new projects, Qwen 3.5 is almost always the better choice. The numbers aren't even close on most fronts. But Qwen 3 has specific advantages that matter in real production scenarios.
Head-to-Head Comparison
| Factor | Qwen 3 | Qwen 3.5 |
|---|---|---|
| Flagship Performance | Qwen3-235B-A22B | Qwen3.5-35B-A3B outperforms 235B with ~78x less active compute |
| Modality | Text only | Native multimodal (text + image + video) |
| Instruction Following | IFEval: 87.8 | IFBench: 76.5 (beats GPT-5.2) |
| Long-Context Speed | Standard attention | 8.6-19x faster decode throughput |
| Dense Models | 0.6B to 32B (mature) | MoE only (no dense variants yet) |
| Fine-Tuning Ecosystem | Thousands of community fine-tunes | Still growing |
| Architecture | Standard Transformer | Hybrid linear + standard attention (from Qwen3-Next) |
Choose Qwen 3 When:
- You need a dense model. Qwen 3's 32B dense is unmatched for predictable quantization behavior, straightforward LoRA fine-tuning, and simpler deployment without MoE routing overhead. Qwen 3.5 doesn't offer dense variants.
- You're already in production. Migrating a working Qwen3-based system to 3.5 means re-evaluating prompts, testing edge cases, and potentially re-fine-tuning. If it's working, don't fix it.
- You only need text. Qwen 3 doesn't carry the overhead of vision and video encoders. For pure text workloads, that's wasted compute in a 3.5 model.
- Fine-tuning is your workflow. Qwen 3 has six months of community LoRAs, Unsloth integrations, and battle-tested training recipes. The Qwen 3.5 ecosystem is catching up but isn't as deep yet.
Choose Qwen 3.5 When:
- Starting a new project. Why build on the previous generation when the current one is better on almost every axis?
- You need vision or video understanding. Qwen 3 is text-only. Period.
- Long-context speed matters. The 8.6-19x decode throughput advantage at long sequences isn't something you can optimize away.
- You want the best per-FLOP performance. Qwen3.5-35B-A3B delivering flagship-class results with 3B active parameters is the most compute-efficient option available right now.
Benchmarks: How Qwen 3 Models Compare
Three models define the Qwen 3 performance tier: the 235B flagship, the 32B dense workhorse, and Qwen3-Next's hybrid efficiency play. Here's how they stack up across reasoning, coding, and general tasks — including where they fall short.
Qwen3-235B-A22B-Thinking-2507 (Open-Source Flagship)
| Benchmark | Score | Context |
|---|---|---|
| AIME25 | 92.3 | Rivals O4-mini (92.7) — essentially tied |
| LiveCodeBench v6 | 74.1 | Beats O4-mini on live coding tasks |
| Arena-Hard v2 | 79.7 | Strong but below Qwen3-Next's 82.7 in Instruct mode |
| MMLU-Pro | 84.4 | Solid knowledge, but proprietary models score higher |
| GPQA Diamond | 81.1 | PhD-level science — behind GPT-5.2's ~92 |
| IFEval | 87.8 | Good instruction following |
The 235B's strength is deep reasoning — math competitions and complex coding. Its weakness? It trails proprietary models on science knowledge (GPQA) and software engineering (SWE-Bench Verified: 75.3 vs Claude Opus 4.5's 80.9). That gap matters if you're building coding agents, but for math and general reasoning, the 235B holds its own against models costing far more to run.
Long-Context Performance (RULER 1M)
| Model | RULER 1M Avg |
|---|---|
| Qwen3-235B-A22B | 92.5 |
| Qwen3-Next-80B-A3B | 91.8 |
| Qwen3-30B-A3B | 86.8 |
Qwen3-Next nearly matches the 235B at 1M tokens while using a fraction of the compute. The 30B-A3B drops off noticeably.

Running Qwen 3 Locally
Every open-weight Qwen 3 model is on Hugging Face in multiple formats. The fastest way to get started:
Ollama (30 Seconds to Running)
ollama run qwen3:8b
That's it. Ollama handles the download, quantization, and chat interface. Other popular tags: qwen3:4b (8 GB VRAM), qwen3:32b (24 GB), qwen3:30b-a3b (MoE, 24 GB). For Qwen3-Next, use the community GGUF builds available on HuggingFace.
vLLM (Production Serving)
vllm serve Qwen/Qwen3-235B-A22B-Instruct-2507 --tensor-parallel-size 4
OpenAI-compatible API with PagedAttention. Qwen3-Next also gets 1.3-2.1x generation speedup with vLLM and SGLang thanks to its Multi-Token Prediction architecture.
llama.cpp (CPU + GPU Hybrid)
./llama-server -m qwen3-8b-q4_K_M.gguf -c 32768 -ngl 35
GGUF quantized models work with partial GPU offloading. Good for machines with limited VRAM. Check our hardware compatibility tool to find which models fit your setup.
Hardware Requirements at a Glance
| GPU / VRAM | Best Qwen 3 Model | Expected Speed |
|---|---|---|
| 4-6 GB | Qwen3-4B (Q4) | ~40 tok/s |
| 8-10 GB | Qwen3-8B (Q4) | ~30 tok/s |
| 16 GB | Qwen3-14B (Q4) | ~20 tok/s |
| 24 GB | Qwen3-32B or 30B-A3B (Q4) | ~15 tok/s (dense) / ~25 tok/s (MoE) |
| 48+ GB | Qwen3-Next-80B-A3B | Variable (hybrid arch) |
| 80+ GB (multi-GPU) | Qwen3-235B-A22B | ~10-15 tok/s with TP=4 |
Tip: GGUF Q4_K_M quantization cuts VRAM by 70-80% with minimal quality loss. For the 30B-A3B, the MoE architecture means only 3B parameters fire per token, so you get 30B-class quality at near-3B speed. Not sure what fits? Use our Can I Run Qwen tool.
API Access and Pricing
If you don't want to self-host, Alibaba Cloud serves Qwen 3 models through DashScope / Model Studio with OpenAI-compatible endpoints. Third-party providers often undercut these prices significantly.
| Model | Provider | Input / 1M tokens | Output / 1M tokens |
|---|---|---|---|
| Qwen3-Max-Thinking | Alibaba Cloud | $1.20 | $6.00 |
| Qwen3-Max-Thinking | Alibaba (long ctx) | $3.00 | $15.00 |
| Qwen3-235B / 30B | OpenRouter | ~$0.10-0.50 | ~$0.50-2.00 |
| Qwen3-Next-80B-A3B | Together AI | $0.50 | $1.20 |
The open-source models run on OpenRouter, Novita AI, Fireworks AI, and Together AI. For cost-sensitive workloads, self-hosting a quantized 30B-A3B on a single 24 GB GPU often beats API pricing after a few million tokens.
Base URL (International): https://dashscope-intl.aliyuncs.com/compatible-mode/v1
Fine-Tuning: Where Qwen 3 Still Leads
This is Qwen 3's strongest argument against moving to 3.5. The fine-tuning ecosystem is six months more mature, with thousands of community LoRAs, proven training recipes, and first-class support in every major framework.
- QLoRA on Qwen3-8B — Fine-tune on a single RTX 4090 using Unsloth for 2-4x speedup and 60% less memory. This is the most battle-tested local fine-tuning setup in the community.
- Qwen3-32B with LoRA — The 32B dense model adapts well to domain-specific tasks. No MoE routing complexity means your LoRA weights apply cleanly and predictably.
- Full fine-tuning — DeepSpeed ZeRO-3 or FSDP for models above 8B. Supported natively by LLaMA-Factory, TRL, and the Hugging Face PEFT library.
If fine-tuning is core to your workflow and you don't need vision, Qwen 3's dense models remain the pragmatic choice. The 3.5 MoE models can be fine-tuned too, but the tooling is younger and the community knowledge base is thinner.
Qwen 3 Timeline
| Date | Release | Significance |
|---|---|---|
| Apr 2025 | Qwen3 Base Models | 8 open-weight models (0.6B-235B), Apache 2.0, hybrid thinking |
| Jun 2025 | Qwen3-Embedding | Text embeddings and reranking (0.6B / 8B) |
| Jul 2025 | Qwen3-2507 Update | Dedicated Instruct/Thinking splits, 256K context, massive performance gains |
| Jul 2025 | Qwen3-Coder | 480B-A35B agentic coding model (67% SWE-Bench Verified) |
| Sep 2025 | Qwen3-Next-80B-A3B | Hybrid GatedDeltaNet architecture, 10x throughput, 262K-1M context |
| Sep 2025 | Qwen3-Max | 1T+ closed-source flagship |
| Oct 2025 | Qwen3-VL models | Vision-Language (2B-32B) |
| Jan 2026 | Qwen3-Max-Thinking | Test-time scaling, #1 on HLE with search |
| Feb 2026 | Qwen3-Coder-Next | 80B-A3B coding model, 70.6% SWE-Bench Verified |
| Feb 2026 | Qwen 3.5 launch | Next generation — surpasses Qwen 3 across the board |
Honest Limitations
No model is perfect, and pretending otherwise doesn't help anyone. Here's where Qwen 3 falls short:
- SWE-Bench gap. On real-world software engineering (SWE-Bench Verified), even the Qwen3-Max-Thinking flagship scores 75.3 — behind Claude Opus 4.5 (80.9) and GPT-5.2 (80.0). If autonomous coding is your primary use case, Qwen 3 isn't the strongest option.
- Benchmaxing concerns. The Qwen 3 lineup posts remarkable benchmark numbers, particularly on math and reasoning tasks. AI researcher Nathan Lambert's framing is useful here: these are "legitimately fantastic models that happen to have insane benchmark scores." The real-world experience often lags behind what the scores suggest, especially on novel problems.
- MoE memory overhead. The 235B-A22B activates only 22B parameters per token, but you still need to load all 235B weights into memory. That means ~80+ GB VRAM minimum, even quantized. The "active parameters" number is about compute cost, not memory cost.
- No multimodal support. Qwen 3 base models are text-only. Vision requires the separate Qwen3-VL models, and video requires Qwen3-Omni. Qwen 3.5 unified all modalities into a single architecture.
- Closed-source flagship. The most powerful Qwen 3 model — Qwen3-Max — can't be self-hosted or fine-tuned. If you need the best Qwen 3 performance, you're locked into Alibaba's API.
These are real trade-offs, not dealbreakers. For most users running an 8B or 32B locally, the limitations above don't apply. But if you're evaluating Qwen 3 for a new enterprise deployment, factor them in — and seriously consider whether Qwen 3.5 resolves them for your use case.
Frequently Asked Questions
Is Qwen 3 still worth using in 2026?
Yes, for specific use cases. The dense models (especially 8B and 32B) remain the best choice for fine-tuning workflows. Existing production deployments shouldn't migrate just because 3.5 exists — if your Qwen 3 setup works, the switching cost rarely justifies the marginal gains. But for new projects, start with Qwen 3.5 unless you specifically need a dense architecture.
Qwen3-Next or Qwen3.5-35B-A3B?
For new deployments, Qwen3.5-35B-A3B. It inherits Qwen3-Next's hybrid architecture but with better training, native multimodal support, and stronger benchmarks. Qwen3-Next makes sense if you're already invested in the Qwen 3 ecosystem and don't want to migrate, or if you need the specific 80B-scale behavior for your fine-tuned pipeline.
What's the best Qwen 3 model for a 24 GB GPU?
Two strong options. Qwen3-32B (dense, Q4 quantized) is better for creative writing and fine-tuning — it's predictable and well-understood. Qwen3-30B-A3B (MoE) is faster at inference since only 3B parameters activate per token, and it scores higher on reasoning benchmarks. Pick based on whether you prioritize speed or fine-tuning flexibility.
Are all Qwen 3 models free for commercial use?
Every open-weight model (0.6B through 235B, including Qwen3-Next) ships under Apache 2.0 — unrestricted commercial use, modification, and distribution. The only proprietary model is Qwen3-Max, which is API-only.
How does Qwen 3 handle tool calling?
Natively. Define your tools as JSON schemas and the model generates structured function calls — compatible with the Model Context Protocol (MCP). No custom parsing needed. The 2507 variants and Qwen3-Next are noticeably better at tool use than the original April models.
Can I use Qwen3-Next in Ollama?
Yes. Community-built GGUF quantizations are available on HuggingFace, and you can load them into Ollama with a custom Modelfile. The official Ollama library also carries Qwen3-Next tags. Given its 80B total but only 3B active parameters, inference speed is surprisingly fast — though you'll need enough RAM or VRAM to load the full 80B weights even if only 3B fire per token.
What happened to Qwen 2.5? Should I skip straight to Qwen 3?
Qwen 2.5 was the previous generation before Qwen 3. At this point, there's no reason to start a new project on Qwen 2.5 — Qwen 3 outperforms it across the board at every size, and the 2507 update widened the gap further. Some specialized Qwen 2.5 fine-tunes still circulate (the 72B was extremely popular for creative writing), but for general use, Qwen 3 is strictly better.