Qwen 3.5: The Complete Guide to Every Model in the Family
Qwen 3.5 isn't a single model. It's a family of eight open-weight models ranging from 0.8B to 397B parameters, all released under Apache 2.0, all natively multimodal (text, image, video), and all built on a hybrid architecture that mixes linear attention with traditional transformers. The lineup dropped in waves between February 16 and March 2, 2026, and it represents the biggest leap in open-weight AI since the original Llama release.
What makes Qwen 3.5 different from yet another model dump? Three things. First, every model — even the 0.8B — handles images and video out of the box. No separate "VL" variant. Second, the hybrid DeltaNet architecture makes long-context inference dramatically faster (up to 19x at 256K tokens). Third, the smaller models punch absurdly above their weight: the 9B beats GPT-OSS-120B on multiple knowledge benchmarks. That's a 13x size difference.
This guide covers all eight open-weight models plus the API-only variants: Qwen3.5-Max-Preview, Qwen3.5-Plus, and the newest addition — Qwen3.5-Omni, a natively omnimodal model released on March 30, 2026, capable of processing and generating text, images, audio, and video. We'll tell you which one to pick, what hardware you need, where the models genuinely shine, and where they fall short.

Which Qwen 3.5 Model Should You Use?
This is the question that matters. Not everyone needs a 397B flagship — in fact, most users will get better results from a smaller, faster model. Here's the quick breakdown by hardware tier:
For Local Use
Pick: 4B or 2B
The 4B is the community favorite for coding — stable, consistent, no performance drops. The 2B handles chat and summarization well. The 0.8B works for embedded or edge use cases.
Pick: 9B (Q4)
The sweet spot. Fits comfortably in 6GB at Q4 quantization, leaving room for context. Beats GPT-OSS-120B on knowledge benchmarks. Works great for agentic coding on an RTX 3060.
Pick: 35B-A3B (Q4) or 27B (Q4)
The 35B-A3B activates only 3B params per token — 196 tok/s on an RTX 4090. Blazing fast. The 27B is slower (~35 tok/s) but denser, better for creative writing and complex reasoning.
Pick: 122B-A10B or 397B-A17B
The 122B is the middle ground — strong quality, reasonable speed. The 397B is the flagship for those with multi-GPU rigs or 256GB+ Macs.
For API Use
Best quality: Qwen3.5-Max-Preview sits at rank 10 on LMArena's Expert leaderboard, beating GPT-5.4. No public API yet — preview only via arenas.
Production: Qwen3.5-Plus at $0.26/M input tokens. That's roughly 70% cheaper than GPT-5 series calls.
Budget: Qwen3-Max-Thinking still holds up well for batch workloads where you don't need the latest generation.
Not sure what'll run on your GPU? Check your hardware with our Can I Run tool — it covers every Qwen 3.5 model and quantization level.
Complete Model Overview
| Model | Active Params | Type | VRAM (Q4) | Best For |
|---|---|---|---|---|
| 397B-A17B | 17B | MoE | ~220 GB | Frontier tasks, maximum quality |
| 122B-A10B | 10B | MoE | ~70 GB | High-quality balance, multi-GPU setups |
| 35B-A3B | 3B | MoE | ~22 GB | Speed-optimized coding, batch work, agents |
| 27B | 27B | Dense | ~16 GB | Creative writing, complex reasoning |
| 9B | 9B | Dense | ~6 GB | Best value overall, agentic coding |
| 4B | 4B | Dense | ~3 GB | Coding (community favorite), lightweight tasks |
| 2B | 2B | Dense | ~2 GB | Chat, summarization, edge deployment |
| 0.8B | 0.8B | Dense | ~1 GB | Embedded, IoT, mobile |
MoE vs Dense: Why It Matters for You
Five of the eight models (27B, 9B, 4B, 2B, 0.8B) are dense — every parameter fires on every token. Simple to run, consistent quality, straightforward VRAM math.
The other three (397B, 122B, 35B) use Mixture of Experts (MoE). They carry more total parameters but only activate a fraction per token. This makes them faster at inference — but they still need enough memory to hold all the experts on disk.
The 35B-A3B is the standout example. It has 35 billion total parameters but activates only 3 billion per token. The result: 196 tok/s on an RTX 4090 — faster than a dense 9B model despite having nearly 4x the total knowledge. The r/LocalLLaMA community calls it "the model that's all you need" for practical day-to-day tasks. On an RTX 3090, it still hits 111 tok/s at Q4.
The 27B Dense, by contrast, activates all 27B parameters on every token. Slower (~35 tok/s on a 3090) but denser computation. If you're doing creative writing or nuanced reasoning where every parameter counts, the 27B often produces more consistent prose. For speed-sensitive batch work, coding agents, or anything where throughput matters — the 35B-A3B wins hands down.
In This Guide
Hardware Requirements & Running Qwen 3.5 Locally
Every Qwen 3.5 model is available on HuggingFace with GGUF quantizations from Unsloth. The table below shows VRAM requirements across quantization levels — find your GPU's VRAM and read across to see what fits.
| Model | Q4_K_M | Q8_0 | BF16 (full) |
|---|---|---|---|
| 0.8B | ~1 GB | ~1 GB | ~2 GB |
| 2B | ~2 GB | ~2 GB | ~4 GB |
| 4B | ~3 GB | ~5 GB | ~8 GB |
| 9B | ~6 GB | ~10 GB | ~18 GB |
| 27B | ~16 GB | ~28 GB | ~54 GB |
| 35B-A3B | ~22 GB | ~38 GB | ~70 GB |
| 122B-A10B | ~70 GB | ~128 GB | ~244 GB |
| 397B-A17B | ~220 GB | ~400 GB | ~780 GB |
The sweet spots: The 9B at Q4 fits in 6GB — any modern GPU handles it. If you have 24GB (RTX 3090/4090), the 35B-A3B at Q4 is phenomenal: 196 tok/s on a 4090, 111 tok/s on a 3090. For pure quality over speed, the 27B Dense at Q4 needs ~16GB and excels at creative writing and complex reasoning.
Quantization quality matters. Community testing from Benjamin Marie shows Q8_0 adds only +0.002-0.05 perplexity over full precision — practically lossless. Q4_K_M is the standard sweet spot. Avoid Q4_0 for coding and factual tasks, where the +0.2-0.25 perplexity hit becomes noticeable.
Quick Start Commands
# llama.cpp (recommended)
./llama-server -m Qwen3.5-9B-Q4_K_M.gguf -c 32768
# Ollama (see warning below)
ollama pull qwen3.5:9b
# MLX on Mac
mlx_lm.generate --model mlx-community/Qwen3.5-35B-A3B-4bitWarning — Ollama has serious issues with Qwen 3.5 as of March 2026. Users on r/LocalLLaMA report infinite chain-of-thought loops, completely broken tool calling (issue #14493), speeds of 15-20 tok/s where llama.cpp gets 100+ tok/s for the same model, and non-functional vision (mmproj files aren't bundled). We recommend llama.cpp server or vLLM until Ollama patches land — typically 2-4 weeks after a major release. LM Studio's thinking mode toggle is also unreliable (issue #1559).
Frameworks that work well: llama.cpp (best for single-GPU), vLLM (best for serving), MLX (best for Apple Silicon). For a full walkthrough, see our guide to running Qwen locally.
Want to check exactly which Qwen 3.5 model fits your specific GPU? Our hardware checker covers every model and quantization.
Benchmarks: Where Qwen 3.5 Wins (and Where It Doesn't)
The Flagship: 397B-A17B vs Frontier Models
The 397B is Alibaba's bid for the frontier. It competes directly with GPT-5.2, Claude Opus, and Gemini 3 Pro — and wins in specific areas while trailing in others. Here's the honest picture:
| Benchmark | Qwen3.5-397B | Notable Competitor |
|---|---|---|
| MMLU-Pro (knowledge) | 87.8 | Claude Opus: 89.5 |
| GPQA Diamond (science) | 88.4 | GPT-5.2: 92.4 |
| IFBench (instruction following) | 76.5 | GPT-5.2: 75.4 |
| SWE-bench Verified (coding) | 76.4 | Claude Opus: 80.9 |
| LiveCodeBench v6 | 83.6 | Gemini 3 Pro: 90.7 |
| MathVision (multimodal math) | 88.6 | GPT-5.2: 83.0 |
| Terminal-Bench 2.0 | 52.5 | Qwen3-Max: 22.5 |
| BrowseComp (browser agent) | 69.0 | GPT-5.2: 65.8 |
The 397B leads on instruction following, multimodal math, document understanding, and every agentic benchmark. It falls behind on competitive coding (Gemini 3 Pro dominates LiveCodeBench) and doctoral-level science (GPT-5.2 edges it on GPQA). For agentic tasks, the jump from Qwen 3's Terminal-Bench score of 22.5 to 52.5 is staggering — that's the single biggest generational improvement in the entire benchmark suite.
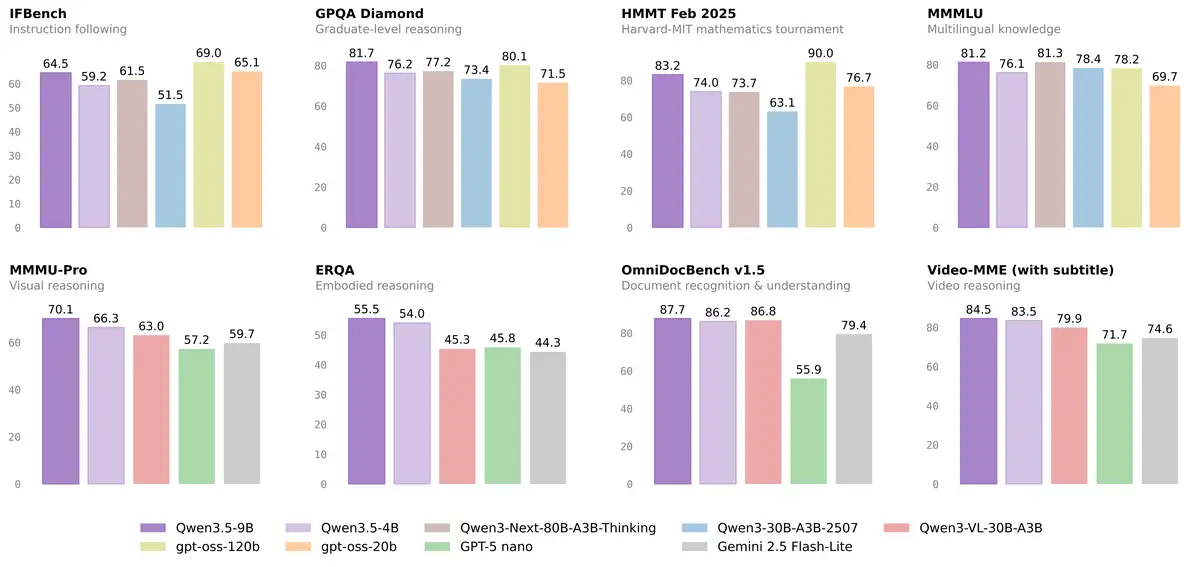
The Giant Killers: 9B and 35B-A3B
This is where the story gets interesting for most users. The 9B — a model that fits on any modern GPU — outscores GPT-OSS-120B across multiple knowledge benchmarks. That's a model 13 times smaller beating a much larger competitor:
| Benchmark | Qwen3.5-9B | GPT-OSS-120B (13x bigger) |
|---|---|---|
| MMLU-Pro | 82.5 | 80.8 |
| GPQA Diamond | 81.7 | 80.1 |
| MMMLU | 81.2 | 78.2 |
| MMMU-Pro | 70.1 | 59.7 |
But here's the caveat you won't find in the headlines: on coding benchmarks, GPT-OSS-120B still wins by a wide margin. LiveCodeBench: 82.7 vs 65.6. The "9B beats 120B" narrative is accurate for knowledge and reasoning — it's misleading if you're primarily looking for a code model. For coding, the 4B is actually more popular in the community: it's stable, consistent, with no performance drops on classification, code fixing, and summarization tasks.
The 35B-A3B pulls off something even more surprising. Despite activating only 3B parameters per token, it beats the previous-generation Qwen3-235B-A22B on core benchmarks. Community speed tests show it hitting 196 tok/s on an RTX 4090 and 60-70 tok/s on an M4 Max via MLX. The Artificial Analysis Intelligence Index rates it at 37 — more than double the median score of 15 for its class.
Qwen3.5-Max-Preview: The API Dark Horse
Alibaba's closed-source Qwen3.5-Max-Preview debuted on LMArena on March 19, 2026. It ranks 10th on the Expert leaderboard with a score of 1498, surpassing GPT-5.4. No public API yet — the pattern from previous releases suggests 2-3 months before general availability.
One broader caveat worth mentioning: AI researcher Nathan Lambert has noted that while Qwen 3.5 models are "legitimately fantastic," the benchmark-first development approach raises questions about real-world generalization. The models score extraordinarily well on structured evaluations — whether that translates equally to messy, real-world tasks is something the community is still figuring out.
How the Hybrid Architecture Works
You don't need to understand the architecture to use Qwen 3.5. But if you're wondering why it's so much faster than Qwen 3 at long contexts, here's the short version.
Standard transformers use quadratic attention — processing cost grows with the square of context length. Qwen 3.5 replaces 75% of its attention layers with Gated DeltaNet, a linear attention mechanism. The remaining 25% use traditional gated attention. This 3:1 ratio (three DeltaNet layers, one full attention layer) gives the model linear scaling for most of the computation while preserving full attention where it matters most.
The practical result: 8.6x faster decoding at 32K tokens and 19x faster at 256K tokens compared to Qwen3-Max. That's not a benchmark artifact — it's a fundamental architectural advantage that shows up in every deployment scenario from local inference to API serving.

All eight models share this hybrid backbone. They also share a 248,320-token vocabulary (up from 152K in Qwen 3), FP8 native precision that cuts activation memory by roughly 50%, and support for 201 languages. The MoE models (397B, 122B, 35B) add expert routing on top — the 397B runs 512 total experts with 11 active per token, while the 35B uses 256 experts with 9 active.
Multimodal: Every Model Sees Images and Video
Previous Qwen generations separated text and vision into different model variants. Qwen 3.5 merges them — every single model from 0.8B to 397B handles text, images, and video through early fusion. No adapter, no separate checkpoint, no "VL" suffix to hunt for.
On document understanding (OmniDocBench1.5), the 397B scores 90.8 — the highest of any model tested, including GPT-5.2 and Gemini 3 Pro. It handles charts, tables, handwritten notes, and multi-page PDFs. On MathVision (multimodal math reasoning), it scores 88.6, beating GPT-5.2's 83.0.

Video input works up to 2 hours in length. Community testers fed it wildlife footage and got accurate animal counts, species identification, and location guesses. The practical use cases range from code generation from wireframes (hand-drawn sketch to functional HTML/CSS) to medical imaging analysis, where testers report structured diagnostic outputs across radiology, pathology, and dermatology — all from a single prompt. For image generation rather than understanding, see Qwen-Image-2.0.
Agentic Capabilities: Terminal-Bench, Browser, Mobile
The 397B leads every agent-focused benchmark. BrowseComp (browser automation): 69.0, beating GPT-5.2 and Claude Opus. NOVA-63 (general agent tasks): 59.1, top of the field. AndroidWorld (mobile app control): 66.8 — a benchmark where competitors haven't even published scores yet.
The Terminal-Bench 2.0 jump tells the real story. Qwen3-Max-Thinking scored 22.5. The Qwen3.5-397B scores 52.5. That's a 2.3x improvement in one generation on a benchmark that measures real terminal interaction — running commands, debugging errors, managing files. It also powers Qwen Code, Alibaba's CLI for delegating coding tasks through natural language.
The model supports native function calling, structured JSON output, and tool use through an OpenAI-compatible API. For teams building AI agents that interact with browsers, mobile apps, or development environments, the combination of strong agentic scores and Apache 2.0 licensing makes it a practical choice without vendor lock-in.
API Access & Pricing
Qwen3.5-Plus is the production API, available through Alibaba Cloud's Model Studio. It's based on the 397B architecture with a 1M context window and built-in tool integration.
| Context Range | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| 0-256K tokens | $0.40 | $2.40 |
| 256K-1M tokens | $1.20 | $7.20 |
That's roughly 70% cheaper than GPT-5 series API calls. Batch mode gives another 50% off for async processing. Thinking mode costs the same as standard — no surcharge. VentureBeat reported that Qwen3.5-Plus responds in 1/6th the time of Claude Sonnet 4.6, making it competitive on both cost and latency.
Quick Start (Python)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_DASHSCOPE_API_KEY",
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1"
)
response = client.chat.completions.create(
model="qwen3.5-plus-2026-02-15",
messages=[
{"role": "user", "content": "Explain quantum entanglement simply."}
],
extra_body={"enable_thinking": True}
)
print(response.choices[0].message.content)The API is OpenAI-compatible — swap the base URL and key in any existing OpenAI SDK integration. It supports multimodal input (images, video), structured JSON output, and function calling. Free testing is available on chat.qwen.ai with rate limits.
Real-World Performance: What the Community Reports
Official benchmarks tell one story. What happens on actual GPUs in actual homes tells another. Here's what r/LocalLLaMA users, Unsloth, and independent testers have found.
Speed by GPU (Measured, Not Claimed)
| GPU | Model | Speed |
|---|---|---|
| RTX 4090 (24GB) | 35B-A3B Q4 | ~196 tok/s |
| RTX 3090 (24GB) | 35B-A3B Q4 | ~111 tok/s |
| RTX 3090 (24GB) | 27B Q4_K_M | ~35 tok/s |
| RTX 3060 (12GB) | 9B Q4 | Works well for agentic coding |
| M4 Max (64GB) | 35B-A3B Q4 MLX | 60-70 tok/s |
| M1 Ultra (64GB) | 35B-A3B Q4 262K ctx | ~44 tok/s |
| M3 Max (48GB) | 397B Q4 (LLM in a Flash) | ~5.5 tok/s |
The 35B-A3B vs 27B numbers highlight the MoE advantage clearly. Both fit on a 24GB card, but the MoE model runs 3-5x faster because it activates fewer parameters. The trade-off: several r/LocalLLaMA users note the 35B-A3B can get "repetitive" in creative prose, while the 27B produces more varied writing. Pick based on your workload.
Thinking Mode: What You Need to Know
Qwen 3.5 does not support the /think and /nothink toggles from Qwen 3 / QwQ. Instead, thinking is controlled via the API parameter enable_thinking. It's on by default for the larger models (27B, 35B, 122B, 397B) and off by default for smaller ones (0.8B, 2B, 4B, 9B). One critical tip: never use greedy decoding — output quality degrades noticeably.
Recommended Sampling Parameters
| Mode | Temperature | Top-P | Top-K | Presence Penalty |
|---|---|---|---|---|
| Thinking | 0.6 | 0.95 | 20 | 1.5 |
| Non-thinking | 0.7 | 0.8 | 20 | 1.5 |
| Coding | 0.7 | 0.8 | 20 | 1.05 |
Fine-Tuning Notes
Unsloth recommends bf16 LoRA for Qwen 3.5 fine-tuning. QLoRA (4-bit) is not recommended — precision issues cause quality degradation. VRAM requirements: 9B needs ~22GB, 27B needs ~56GB, 35B-A3B needs ~74GB. If you downloaded MXFP4 quants from Unsloth before February 27, re-download — those were retired due to quality concerns.
Full Technical Specifications
Reference table for the technically curious. All models share the hybrid GDN + Attention architecture (3:1 ratio), 248,320-token vocabulary, 262K native context (1M via YaRN), native FP8 precision, and Apache 2.0 licensing.
| Model | Total Params | Active Params | Type | Experts | Layers | Released |
|---|---|---|---|---|---|---|
| 397B-A17B | 397B | 17B | MoE | 512 / 10+1 | 60 | Feb 16 |
| 122B-A10B | 122B | 10B | MoE | 256 / 8+1 | 48 | Feb 24 |
| 35B-A3B | 35B | 3B | MoE | 256 / 8+1 | 40 | Feb 24 |
| 27B | 27B | 27B | Dense | -- | 64 | Feb 24 |
| 9B | 9B | 9B | Dense | -- | 32 | Mar 2 |
| 4B | 4B | 4B | Dense | -- | 32 | Mar 2 |
| 2B | 2B | 2B | Dense | -- | 24 | Mar 2 |
| 0.8B | 0.8B | 0.8B | Dense | -- | 24 | Mar 2 |
March 30, 2026 — Qwen3.5-Omni released. The family expanded with a natively omnimodal model in three variants (Plus, Flash, Light) that can process and generate text, images, audio, and video end-to-end. Qwen3.5-Omni is proprietary and API-only — not open-weight like the eight models above. For full details, benchmarks, and use cases, see our dedicated Qwen-Omni guide.
What Changed from Qwen 3
| Aspect | Qwen 3 | Qwen 3.5 |
|---|---|---|
| Architecture | Standard Transformer | Hybrid GDN + Attention (3:1) |
| Multimodal | Separate VL variant | Unified natively |
| Vocabulary | 152K tokens | 248K tokens |
| Languages | 119 | 201 |
| Decode at 32K | Baseline | 8.6x faster |
| Decode at 256K | Baseline | 19x faster |
| Precision | BF16 | FP8 native (~50% less memory) |
Frequently Asked Questions
Which Qwen 3.5 model is best for coding?
The 4B is the community favorite — stable outputs, no performance drops, fast. For agentic coding (multi-file edits, running commands), step up to the 9B on an RTX 3060 or better. If you have 24GB VRAM, the 35B-A3B gives you both speed and quality. One thing to keep in mind: the 9B beats larger models on knowledge benchmarks but trails on LiveCodeBench, so pure competitive coding isn't its strength.
Can I run Qwen 3.5 on an RTX 3060 (12GB)?
Yes. The 9B fits in ~6GB at Q4 quantization — you'll have room for a decent context window. The 4B needs only ~3GB. Even the 35B-A3B can work with partial offloading, though performance takes a hit. Use our Can I Run tool for specific numbers.
35B-A3B vs 27B — which should I pick?
The 35B-A3B (MoE) activates only 3B parameters per token. It's ultra-fast: 196 tok/s on a 4090 vs ~35 tok/s for the 27B. Best for coding agents, batch processing, and anything where speed matters. The 27B (Dense) fires all parameters, producing richer output for creative writing and nuanced reasoning. If your workload is interactive chat or creative prose, go 27B. For everything else, 35B-A3B.
Does Ollama work with Qwen 3.5?
Partially, with significant issues as of March 2026. Known problems include infinite chain-of-thought loops, broken tool calling (issue #14493), and 5-7x slower speeds compared to llama.cpp for the same model. Vision doesn't work because mmproj files are bundled separately. We recommend llama.cpp server or vLLM until patches ship — usually 2-4 weeks after a major release.
When will Qwen3.5-Max be available via API?
No official date. The Qwen3.5-Max-Preview appeared on LMArena on March 19, 2026. Based on Alibaba's previous release patterns, a public API typically follows 2-3 months after arena previews.
Is Qwen 3.5 better than Llama?
On structured benchmarks, Qwen 3.5 models show roughly 40% better reasoning efficiency at comparable sizes, according to community analysis. For coding, RAG pipelines, and multilingual use, Qwen consistently comes out ahead. Llama still has a larger ecosystem and may feel more natural for casual English chat. The honest answer: it depends on your use case. For a detailed comparison, see our model comparison guides.
Can I fine-tune Qwen 3.5?
Yes, with caveats. Use bf16 LoRA (Unsloth recommended). QLoRA 4-bit is not recommended — it causes precision issues specific to the hybrid architecture. VRAM needs: 9B requires ~22GB, 27B requires ~56GB, 35B-A3B requires ~74GB. All models are Apache 2.0, so no licensing restrictions.
What comes after Qwen 3.5?
Alibaba is already testing the next generation. Qwen3.6-Plus-Preview is available for early testing, signaling that the Qwen 3.6 family is in active development. If the jump from Qwen 3 to 3.5 is any indication, expect significant architectural and performance improvements. See our Qwen-Plus page for the latest on preview availability.
Bottom Line
Qwen 3.5 isn't just a flagship model — it's an entire family that covers everything from edge deployment to frontier reasoning, all under Apache 2.0. The 9B punches way above its weight on knowledge tasks. The 35B-A3B is absurdly fast for its quality level. The 397B competes with the best closed models on agentic and multimodal benchmarks.
The caveats are real: Ollama support isn't stable yet, the 9B's coding scores don't match its knowledge scores, and the benchmark-first approach raises fair questions about real-world generalization. But for anyone building with open models in 2026, this family is the new baseline to evaluate against.
Start with the 9B if you want the best value. Move to the 35B-A3B if you want speed. Go 27B if you want quality. And if you're building AI agents — the 397B leads every benchmark in that category.