
Qwen3-ASR: Alibaba's Open-Source Speech Recognition System
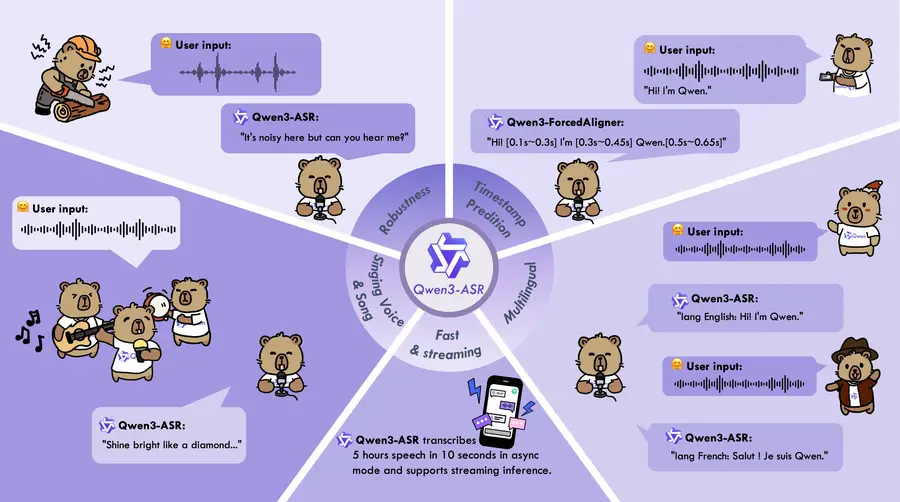
Qwen3-ASR is Alibaba Cloud's open-source automatic speech recognition system, released on January 30, 2026. It supports 52 languages and dialects (including 22 Chinese dialects), handles both streaming and offline transcription from a single unified model, and achieves state-of-the-art accuracy across Chinese, multilingual, and even singing voice benchmarks. The entire family is released under the Apache 2.0 license, making it one of the most capable open-source ASR systems available today.
What sets Qwen3-ASR apart from alternatives like Whisper or GPT-4o Transcribe isn't just raw accuracy — it's the combination of capabilities packed into a single lightweight model. It can transcribe noisy environments, recognize singing voices over background music, provide word-level timestamps via its companion ForcedAligner model, and switch seamlessly between streaming and offline modes. For context on the broader model family, see the Qwen 3 overview.
In This Guide
Model Variants
The Qwen3-ASR family includes three open-source models and one cloud-only API variant:
| Model | Parameters | Type | License |
|---|---|---|---|
| Qwen3-ASR-1.7B | ~2B (1.7B LLM + encoder + projector) | Best quality, offline & streaming | Apache 2.0 |
| Qwen3-ASR-0.6B | ~0.9B (0.6B LLM + encoder + projector) | Faster, lower VRAM | Apache 2.0 |
| Qwen3-ForcedAligner-0.6B | ~0.9B | Word-level timestamp alignment | Apache 2.0 |
| Qwen3-ASR-Flash (API only) | Not disclosed | Cloud real-time API via DashScope | Proprietary |
The 1.7B variant is the flagship for accuracy, while the 0.6B model offers a compelling trade-off — achieving a real-time factor (RTF) of 0.064, meaning it can transcribe roughly 2,000 seconds of speech per second at high concurrency. Both models share the same architecture and support the same 52 languages.
Architecture: Audio Transformer + Qwen3 LLM
Qwen3-ASR uses a three-component architecture built on top of the Qwen3-Omni foundation:
- AuT Encoder — A pretrained Audio Transformer that performs 8x downsampling on Fbank features (128 dimensions), producing a 12.5Hz token rate. The 1.7B variant uses a 300M-parameter encoder with 1024 hidden size; the 0.6B variant uses 180M parameters with 896 hidden size.
- Projector — Bridges the audio encoder's representations to the LLM decoder's embedding space.
- LLM Decoder — A Qwen3-1.7B or Qwen3-0.6B language model that generates the text output autoregressively.
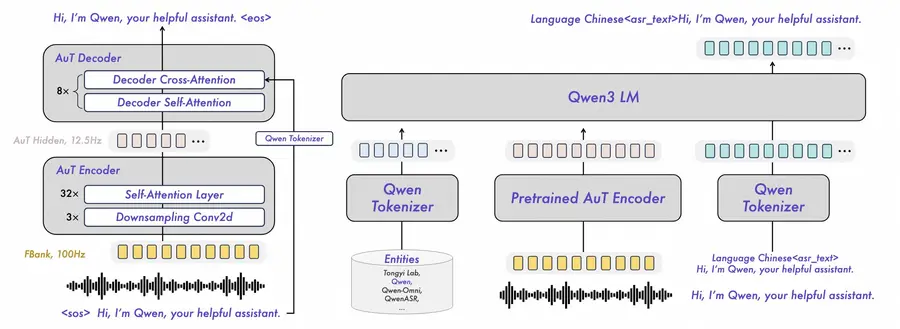
A key innovation is the dynamic flash attention window that ranges from 1 to 8 seconds. This allows a single model to handle both streaming (low-latency, real-time) and offline (full-context, higher accuracy) inference without needing separate model weights.
Training Pipeline
The model was trained through a rigorous four-stage pipeline:
- AuT Pretraining — Approximately 40 million hours of pseudo-labeled ASR data, primarily Chinese and English.
- Omni Pretraining — Multi-task training with 3 trillion tokens covering audio, vision, and text (as part of the Qwen3-Omni foundation).
- ASR Supervised Fine-Tuning — Targeted training on the ASR format with multilingual data, streaming enhancements, and context-biasing data.
- Reinforcement Learning (GSPO) — Group Sequence Policy Optimization with ~50,000 utterances to refine output quality.
Supported Languages: 52 Total
Qwen3-ASR supports 30 languages and 22 Chinese dialects — by far the most comprehensive coverage among open-source ASR models:
The model also handles multilingual code-switching within a single utterance — for example, a speaker mixing English and Chinese in the same sentence without any manual language selection.
Benchmarks & Performance
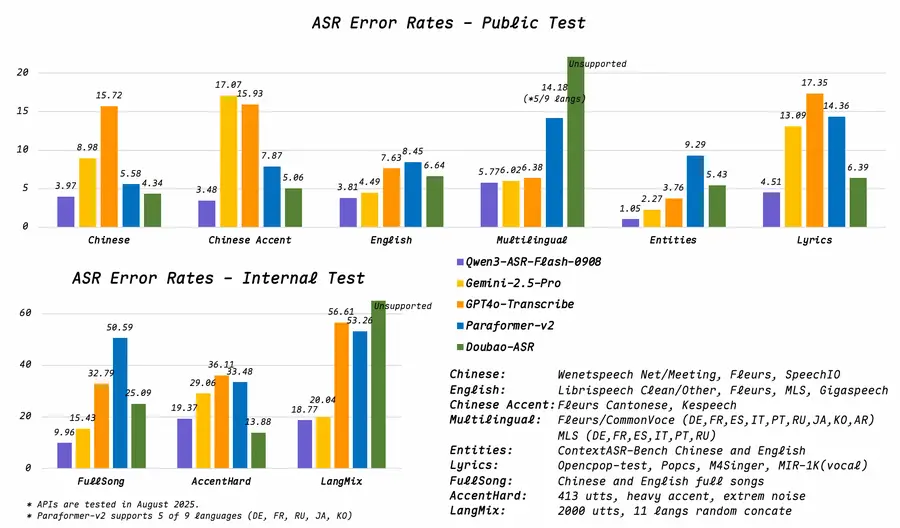
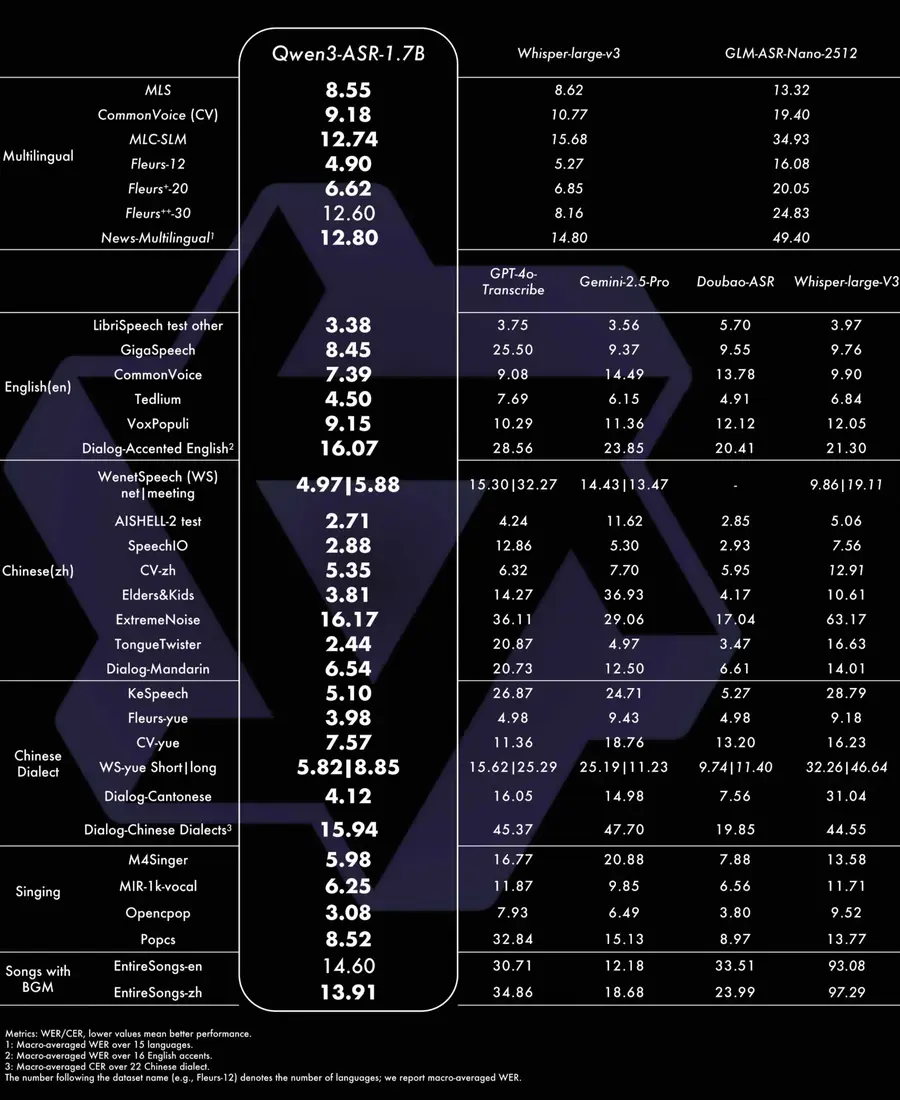
Qwen3-ASR-1.7B achieves state-of-the-art results across multiple categories, significantly outperforming Whisper-large-v3 and GPT-4o-Transcribe in Chinese and multilingual benchmarks:
English ASR (Word Error Rate — lower is better)
| Dataset | Qwen3-ASR-1.7B | Whisper-large-v3 | GPT-4o-Transcribe |
|---|---|---|---|
| LibriSpeech (clean/other) | 1.63 / 3.38 | 1.51 / 3.97 | 1.39 / 3.75 |
| GigaSpeech | 8.45 | 9.76 | — |
| CommonVoice-en | 7.39 | 9.90 | — |
Chinese ASR (Character Error Rate — lower is better)
| Dataset | Qwen3-ASR-1.7B | Whisper-large-v3 | GPT-4o-Transcribe |
|---|---|---|---|
| WenetSpeech (net/meeting) | 4.97 / 5.88 | 9.86 / 19.11 | 15.30 / 32.27 |
| AISHELL-2 test | 2.71 | — | 4.24 |
| SpeechIO | 2.88 | — | 12.86 |
Singing Voice & Background Music (WER)
| Dataset | Qwen3-ASR-1.7B | GPT-4o | Doubao-ASR |
|---|---|---|---|
| M4Singer | 5.98 | 16.77 | 7.88 |
| EntireSongs-en | 14.60 | 30.71 | 33.51 |
| EntireSongs-zh | 13.91 | 34.86 | 23.99 |
The singing voice results are particularly impressive — Qwen3-ASR achieves sub-6% WER on solo singing and sub-15% even on full songs with strong background music, dramatically outperforming all competitors.
Key Differentiating Features
1. Unified Streaming & Offline Model
Most ASR models force you to choose between a streaming model (low latency, lower accuracy) and an offline model (higher accuracy, higher latency). Qwen3-ASR uses a dynamic flash attention window (1–8 seconds) that lets a single set of weights handle both modes. In streaming mode, the 1.7B model maintains a WER of 4.51 on LibriSpeech-other vs. 3.38 in offline — a very small accuracy trade-off for real-time capability.
2. Context Biasing
This is a feature that most open-source ASR models lack entirely. You can provide arbitrary text (up to 10,000 tokens in the API) to bias the transcription toward specific terminology — company names, medical terms, legal jargon, product codes, or any domain-specific vocabulary. The model will prefer these terms when the audio is ambiguous, dramatically improving accuracy in specialized domains.
3. Singing Voice & Music Recognition
Qwen3-ASR can accurately transcribe singing voices even with strong background music — something that destroys the accuracy of virtually every other ASR model. It achieves under 6% WER on solo singing benchmarks and under 15% on full songs with instrumental accompaniment, outperforming GPT-4o by more than 2x.
4. Inverse Text Normalization
The model automatically converts spoken forms to clean written text: numbers, dates, currencies, email addresses, and URLs are formatted properly without any post-processing needed.
How to Run Qwen3-ASR Locally
The Qwen team provides an official Python package that makes deployment straightforward. There are two backends: a basic Transformers backend and a high-performance vLLM backend.
Option 1: Quick Install (Transformers Backend)
The simplest way to get started for testing and light usage.
- Install the package:
pip install -U qwen-asr - Launch the web demo:
qwen-asr-demo Qwen/Qwen3-ASR-1.7B - Or use the streaming demo:
qwen-asr-demo-streaming Qwen/Qwen3-ASR-1.7B
Option 2: vLLM Backend (Recommended for Speed)
For production use or when you need high throughput.
- Install with vLLM support:
pip install -U qwen-asr[vllm] - Launch the OpenAI-compatible server:
qwen-asr-serve Qwen/Qwen3-ASR-1.7B --port 8000
This exposes an OpenAI-compatible API endpoint, enabling drop-in replacement in existing workflows.
Option 3: Docker
For containerized deployments with all dependencies pre-installed.
docker run --gpus all --shm-size=4gb -p 8000:8000 qwenllm/qwen3-asr:latestSupported Audio Inputs
Qwen3-ASR accepts a wide variety of input formats:
- Local files — MP3, WAV, M4A, MP4, MOV, MKV, and more (via FFmpeg)
- HTTP/HTTPS URLs (direct audio links)
- Base64-encoded audio data
- NumPy arrays with sample rate tuples
All inputs are automatically resampled to 16kHz mono.
Hardware Requirements
| Model | Min VRAM | Recommended | RTF (Concurrency 128) |
|---|---|---|---|
| Qwen3-ASR-1.7B | ~4 GB (weights only) | 16 GB+ for batch inference | — |
| Qwen3-ASR-0.6B | ~2 GB (weights only) | 8 GB+ for batch inference | 0.064 |
For more details on running Qwen models locally, check our guide to running Qwen locally and our hardware requirements page.
Cloud API: Qwen3-ASR-Flash
For users who don't want to self-host, Alibaba offers Qwen3-ASR-Flash as a real-time WebSocket API through the DashScope platform. Key details:
| Protocol | WebSocket (WSS) |
| Endpoint (International) | wss://dashscope-intl.aliyuncs.com/api-ws/v1/realtime |
| Pricing (International) | $0.00009/second (~$0.32/hour) |
| Rate Limit | 20 requests per second |
| Audio Formats | PCM, Opus (8 kHz or 16 kHz, mono) |
| Features | Real-time streaming, emotion recognition, context biasing |
The API-only variant also supports features not yet available in the open-source models, including emotion recognition in real-time.
Qwen3-ASR-Toolkit (CLI for Long Audio)
The official Qwen3-ASR-Toolkit provides a command-line tool that overcomes the API's 3-minute audio limit through intelligent chunking:
pip install qwen3-asr-toolkit
qwen3-asr -i audio_file.mp3 -j 4 --save-srtIt handles automatic resampling, Voice Activity Detection (VAD) for smart splitting, parallel processing across multiple threads, SRT subtitle generation, and hallucination removal post-processing.
Qwen3-ForcedAligner: Millisecond-Precision Timestamps
The companion Qwen3-ForcedAligner-0.6B model provides word and character-level timestamps with exceptional precision. It uses a non-autoregressive (NAR) architecture with a "slot-filling" approach to timestamp prediction.
| Language | Qwen3-ForcedAligner | WhisperX | NFA |
|---|---|---|---|
| Chinese | 33.1 ms | — | 109.8 ms |
| English | 37.5 ms | 92.1 ms | 107.5 ms |
| French | 41.7 ms | 145.3 ms | 100.7 ms |
| German | 46.5 ms | 165.1 ms | 122.7 ms |
| Japanese | 42.2 ms | — | — |
| Average | 42.9 ms | 133.2 ms | 129.8 ms |
The ForcedAligner achieves a 67–77% reduction in alignment error compared to WhisperX and NFA, averaging just 42.9ms absolute shift. It supports 11 languages: Chinese, English, Cantonese, French, German, Italian, Japanese, Korean, Portuguese, Russian, and Spanish. This makes it ideal for subtitle generation, karaoke timing, audio editing, and any application requiring precise word-level synchronization.
Qwen3-ASR vs. Whisper vs. GPT-4o Transcribe
How does Qwen3-ASR stack up against the most popular alternatives?
| Feature | Qwen3-ASR-1.7B | Whisper-large-v3 | GPT-4o-Transcribe |
|---|---|---|---|
| Open-source | Yes (Apache 2.0) | Yes | No (API only) |
| Languages | 52 (30 + 22 dialects) | 99 | ~50+ |
| Chinese performance | SOTA (2–3x better) | Moderate | Weak |
| English performance | Competitive | Strong | Strong |
| Singing/BGM | SOTA (<6% WER solo) | Poor | Poor |
| Streaming | Yes (unified model) | No | Yes |
| Forced alignment | Yes (42.9ms avg) | Via WhisperX (133ms) | No |
| Context biasing | Yes (10K tokens) | No | No |
| Self-hostable | Yes | Yes | No |
Whisper still leads in raw language count (99 vs. 52), and GPT-4o edges ahead slightly on clean English benchmarks like LibriSpeech. But Qwen3-ASR dominates in Chinese, multilingual robustness, singing voice recognition, streaming capability, and the forced alignment use case. For most real-world applications — especially those involving noisy audio, multiple languages, or specialized terminology — Qwen3-ASR is the stronger choice. If you want to compare Qwen models against other LLMs more broadly, check our Qwen vs. ChatGPT comparison.
Final Verdict
Qwen3-ASR is a major step forward for open-source speech recognition. It doesn't just match commercial alternatives — it surpasses them in key areas like Chinese transcription, singing voice recognition, and word-level alignment precision. The unified streaming/offline design, context biasing capability, and the lightweight model sizes make it practical for everything from personal projects to production deployments.
The Apache 2.0 license removes any commercial restrictions, and the official Python package makes getting started as simple as pip install qwen-asr. Whether you're building a transcription service, adding speech input to an application, or creating subtitles, Qwen3-ASR deserves serious consideration.
For the companion text-to-speech models, see our Qwen3-TTS guide. Explore the full Qwen 3 family, try Qwen AI Chat, or check our guide to running Qwen models locally.