Qwen Audio
Qwen2-Audio is Alibaba's 8.2 billion parameter audio-language model, released in August 2024. It understands speech, music, and environmental sounds — then reasons about them in natural language. No separate ASR pipeline. You feed it raw audio, optionally with a text prompt, and it responds directly.
Here's the catch: there won't be a Qwen3-Audio. Alibaba folded audio capabilities into their omni models instead. If you're evaluating Qwen's audio stack today, the real question isn't just what Qwen2-Audio can do — it's where the technology went next.
- What Qwen2-Audio Actually Does
- Benchmark Performance
- Architecture and Design
- The Evolution Path: Qwen2-Audio to Qwen3-Omni
- Running Qwen2-Audio Locally
- Which Qwen Audio Model Should You Use?
- FAQ
What Qwen2-Audio Actually Does
Qwen2-Audio operates in two distinct modes, and understanding the difference matters for how you'd integrate it.
Voice Chat mode takes audio-only input. You speak, the model responds with text. There's no text prompt involved — the model figures out what you want from your voice alone. Think of it as a voice assistant backend that skips the traditional speech-to-text-then-LLM pipeline entirely.
Audio Analysis mode combines audio with a text instruction. You give it a recording plus a question like "What emotion is the speaker expressing?" or "Translate this to English." This is the more flexible mode and where most practical applications live.
The tasks it handles span a surprisingly wide range:
| Task | What It Does | Practical Use |
|---|---|---|
| ASR | Speech-to-text across multiple languages (EN, ZH, ES, FR, DE, IT) | Transcription workflows, meeting notes |
| S2TT | Speech-to-text translation (e.g., Chinese speech to English text) | Cross-language content, subtitles |
| SER | Speech emotion recognition — detects anger, joy, sadness, neutral | Call center analytics, UX research |
| VSC | Vocal sound classification (laughter, applause, coughing, etc.) | Audio indexing, accessibility |
| Music Understanding | Identifies genre, instruments, tempo, mood | Content tagging, music libraries |
| Environmental Sound | Detects alarms, glass breaking, sirens, door knocks | Security systems, smart home |
That's a lot of ground for a single model. Most competing systems require separate models for each task — one for ASR, another for sound classification, another for emotion. Qwen2-Audio handles all of them in one 8.2B package. The trade-off? It doesn't beat dedicated models on any single task. Qwen3-ASR, for example, crushes it on pure transcription accuracy.
Benchmark Performance
Alibaba evaluated Qwen2-Audio across 13+ benchmark datasets, covering speech recognition, audio understanding, and conversational ability. The model was tested against both open-source competitors (SALMONN, Gemini 1.5 Pro) and specialized audio systems.
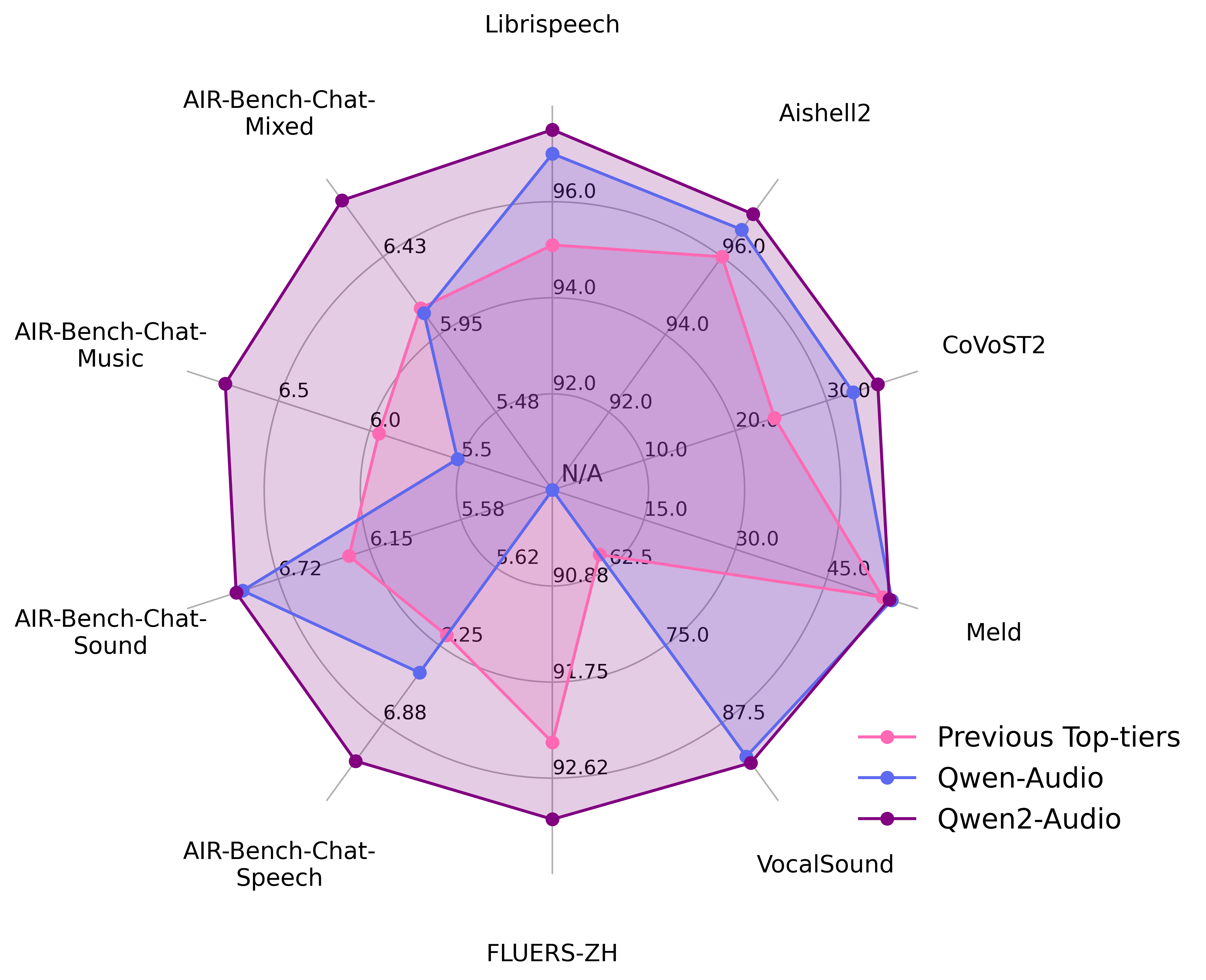
On AIR-Bench — one of the more comprehensive audio evaluation suites — Qwen2-Audio scored 7.18 on the chat dimension and 7.42 on speech understanding, outperforming Gemini 1.5 Pro (6.97 and 7.02 respectively). That's a notable result for an 8B-class model going up against a much larger multimodal system.
For speech recognition, the Librispeech results tell a clear story: 1.6% WER on the clean test set and 3.6% WER on the noisy "other" split. Solid numbers, though not state-of-the-art by 2026 standards — Qwen3-ASR hits 4.50% on Tedlium while processing audio 2000x faster than real-time.
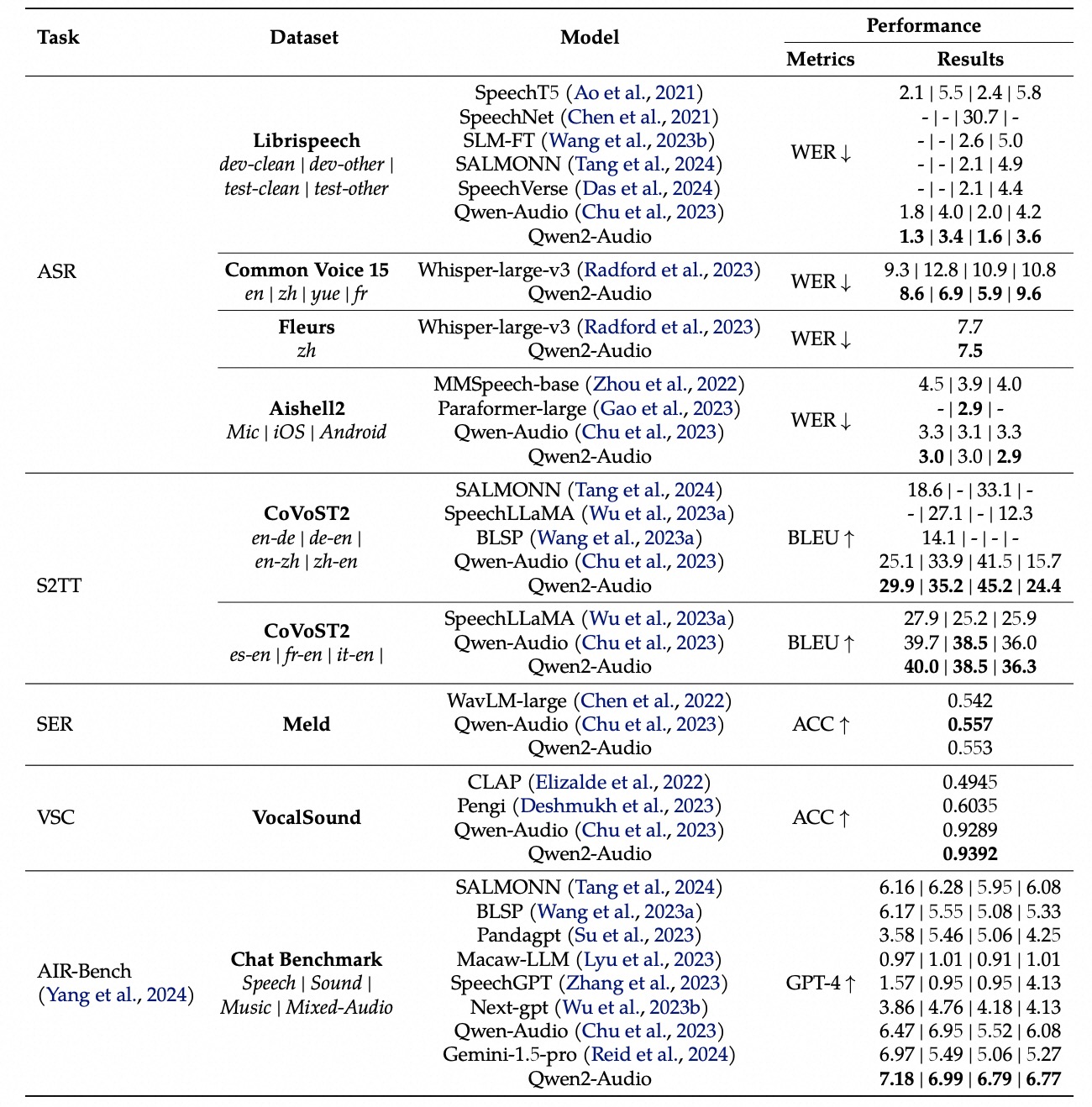
The vocal sound classification task (VocalSound dataset) is where Qwen2-Audio's multi-task design shines — it reaches 93.6% accuracy on classifying coughs, laughter, sighs, and other non-speech vocalizations, all without fine-tuning on that specific dataset.
Where it falls short: on CoVoST2 speech translation, Qwen2-Audio's BLEU scores are decent but not exceptional compared to dedicated translation models. And its speech recognition, while good for a generalist model, can't compete with purpose-built ASR systems on noisy, real-world audio. That's the inherent trade-off of a jack-of-all-trades approach.
Architecture and Design
Qwen2-Audio's architecture pairs two components: a Whisper-large-v2 audio encoder and a Qwen-7B language model. The audio encoder converts raw waveforms into a sequence of audio tokens, which the language model then processes alongside any text input.
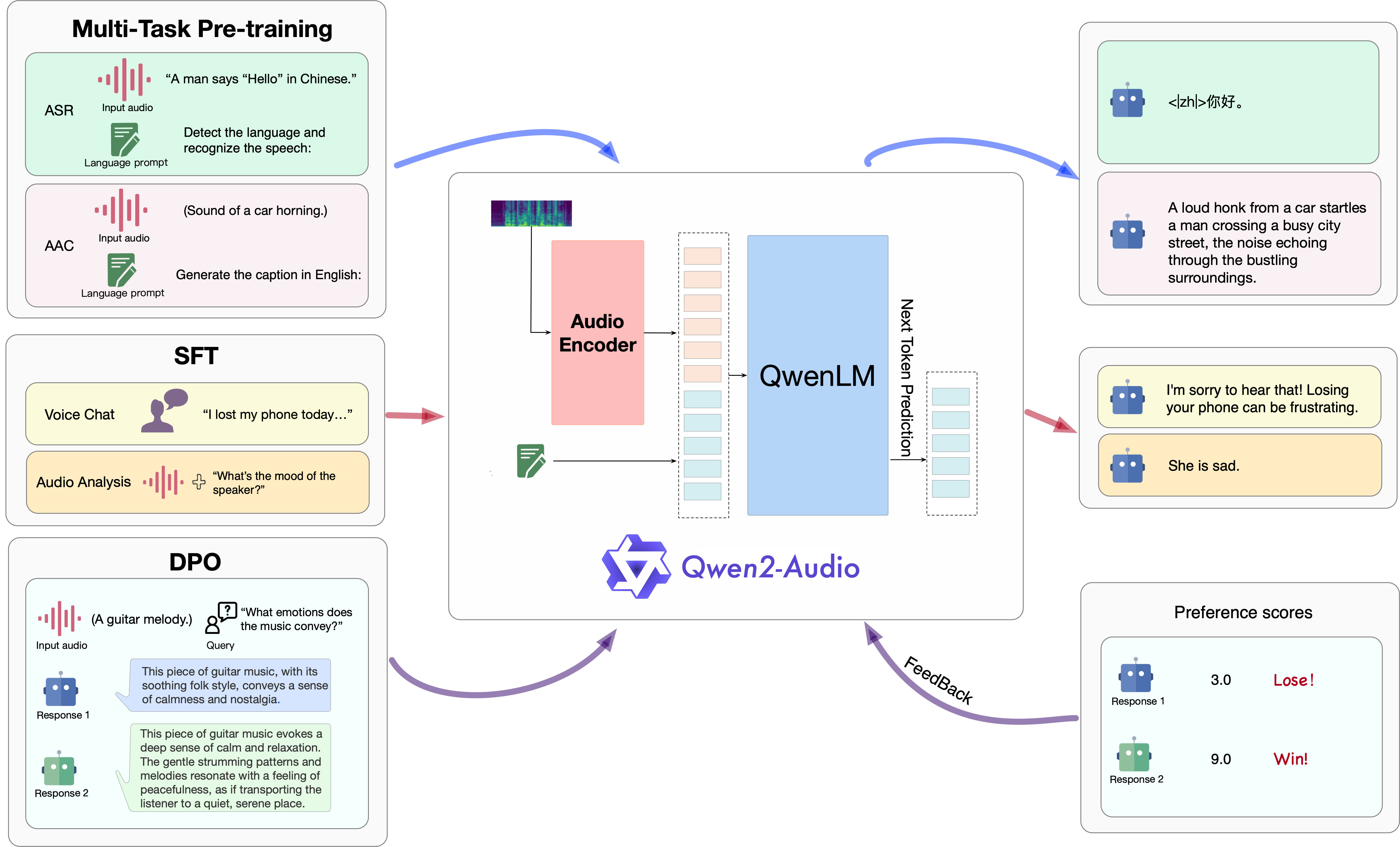
The total parameter count lands at 8.2 billion — 7B from the language model plus roughly 1.2B from the audio encoder. That's a manageable size for local deployment, fitting comfortably in a single 24GB GPU.
One important constraint: the model requires 16 kHz sample rate audio input. Feed it 44.1 kHz or 48 kHz recordings and you'll need to downsample first. This isn't unusual for audio models — Whisper has the same requirement — but it does mean you need a preprocessing step in most production pipelines.
The architecture doesn't support streaming. Audio must be fully captured before processing begins, which rules out real-time applications like live captioning. For those use cases, you'd want Qwen3-Omni or Qwen3-ASR, both of which support streaming inference natively.
The Evolution Path: Qwen2-Audio to Qwen3-Omni
This is the part most coverage misses. Qwen2-Audio isn't a dead-end — it's the starting point of a lineage that evolved rapidly. Understanding where it sits helps you pick the right model today.
| Generation | Model | Release | Audio Capabilities | Key Advance |
|---|---|---|---|---|
| Gen 2 | Qwen2-Audio | Aug 2024 | Audio understanding only (no speech output) | First unified audio-language model |
| Gen 2.5 | Qwen2.5-Omni | Mar 2025 | Audio in + speech out + vision | Added speech generation and visual input |
| Gen 3 | Qwen3-Omni | Sep 2025 | 40-min audio, 49 voices, MoE architecture | SOTA omni, massively scaled audio context |
The jump from Gen 2 to Gen 2.5 was dramatic. Qwen2-Audio could only listen. Qwen2.5-Omni could listen, speak back, and see — all in one model. It added speech generation, which meant the system could carry an actual voice conversation rather than just responding with text.
Then Qwen3-Omni pushed things further. It switched to a Mixture-of-Experts architecture for efficiency, extended audio context to 40 minutes (Qwen2-Audio struggles with anything beyond a few minutes), and added 49 distinct voice options with emotion and style control. By September 2025, it was the most capable open-weight omni model available.
Alongside the omni models, Alibaba also released specialized audio tools in the Qwen3 generation:
- Qwen3-ASR — Dedicated speech recognition covering 52 languages. Significantly more accurate than Qwen2-Audio's built-in ASR, with streaming support and forced alignment for timestamps.
- Qwen3-TTS — Text-to-speech with voice cloning from a 3-second reference clip. Outperforms ElevenLabs on speaker similarity benchmarks (0.789 vs 0.646).
Bottom line: Qwen2-Audio was the proof of concept. The real capabilities live in Qwen3-Omni and the specialized ASR/TTS models now. If you're starting a new project, start there.
Running Qwen2-Audio Locally
Qwen2-Audio is available on HuggingFace as Qwen/Qwen2-Audio-7B-Instruct. For a broader overview of running Qwen models locally, see our dedicated guide. There's a caveat: it requires building Transformers from source rather than using a pip release.
pip install git+https://github.com/huggingface/transformers
pip install accelerate torch torchaudioWith 8.2B parameters at fp16, you're looking at roughly 16-17 GB of VRAM. An RTX 3090 or RTX 4090 handles it without issues. An RTX 3060 12GB won't fit it at fp16 — you'd need to quantize, and quantized audio models tend to degrade noticeably on speech tasks. Check our hardware compatibility tool if you're unsure about your setup.
There's no DashScope API endpoint for Qwen2-Audio specifically. For cloud-based audio inference, Alibaba points users toward the Qwen2.5-Omni or Qwen3-Omni APIs instead, which handle all the same tasks and more.
A practical note: if your only goal is speech-to-text, Qwen3-ASR is dramatically faster and more accurate. Its 0.6B model processes 2,000 seconds of audio in 1 second at batch concurrency — orders of magnitude more efficient than running full audio understanding through Qwen2-Audio's 8.2B parameters.
Which Qwen Audio Model Should You Use?
This is the question that matters. Qwen's audio lineup has grown, and each model serves a different purpose. Here's the honest breakdown:
| Use Case | Best Model | Why |
|---|---|---|
| Speech-to-text (production) | Qwen3-ASR | 52 languages, streaming, timestamps, 2000x real-time speed |
| Voice synthesis / cloning | Qwen3-TTS | 3-second voice cloning, emotion control, 97ms latency |
| Full voice conversation | Qwen3-Omni | Audio in + out, vision, 40-min context, 49 voices |
| Lightweight audio analysis | Qwen2-Audio | Single model for emotion, music, environment sounds — 8.2B, self-hostable |
| Audio + vision combined | Qwen3-Omni | Only option that handles all modalities simultaneously |
Qwen2-Audio still makes sense in one scenario: you want a single, relatively small model that handles diverse audio understanding tasks — emotion detection, sound classification, music analysis, basic transcription — and you don't need speech output or state-of-the-art accuracy on any single task. It's the Swiss Army knife of Qwen audio, even if the dedicated tools cut better individually.
For anything production-facing in 2026, the Qwen3-generation models are the right choice. They're faster, more accurate, and actively maintained. Qwen2-Audio's HuggingFace repo hasn't seen updates since late 2024.
Frequently Asked Questions
Is there a Qwen3-Audio?
No. Alibaba didn't release a standalone Qwen3-Audio model. Audio capabilities in the Qwen3 generation are split between Qwen3-Omni (full multimodal), Qwen3-ASR (speech recognition), and Qwen3-TTS (speech synthesis). The "do-everything audio model" concept evolved into the omni architecture instead.
Can Qwen2-Audio generate speech?
No. It's audio-in, text-out only. For speech generation, use Qwen3-TTS or Qwen3-Omni.
Should I use Qwen2-Audio for speech-to-text?
Only if you also need its other capabilities (emotion recognition, sound classification) from the same model. For dedicated transcription, Qwen3-ASR is better in every dimension — accuracy, speed, language coverage, and streaming support.
What hardware do I need?
A GPU with at least 24GB VRAM (RTX 3090, RTX 4090, A5000) for fp16 inference. The model totals 8.2B parameters at ~16.4GB in fp16. You can try INT8 quantization on 12GB cards, but expect some quality loss on speech tasks. Check your specific GPU here.
Does Qwen2-Audio support real-time streaming?
No. The architecture requires complete audio input before processing. For real-time or streaming use cases, look at Qwen3-ASR (streaming transcription) or Qwen3-Omni (streaming conversation).