
Qwen Embeddings & Rerankers
Qwen3-Embedding is the top-ranked open-source embedding model on MTEB multilingual, scoring 70.58 — ahead of Gemini Embedding and nearly 6 points above OpenAI's text-embedding-3-large. It ships under Apache 2.0, handles 32K tokens (four times OpenAI's limit), and you can run it locally for free.
But embeddings are only half the story. Alibaba released four model families here: text embeddings, text rerankers, multimodal (vision-language) embeddings, and multimodal rerankers. Together, they cover every piece of a modern retrieval pipeline — from initial vector search through reranking to multimodal document retrieval. If you're building RAG, semantic search, or any retrieval system, this is the most complete open-source toolkit available right now.
In This Guide
Which Qwen Embedding Model Should You Use?
Four families, ten models. Here's the quick version:
Your go-to for text-based search, RAG, and semantic similarity. Three sizes: 0.6B, 4B, 8B. The 8B ranks #1 on MTEB multilingual and MTEB Code. Start here if your data is text-only.
Cross-encoder that re-scores your top-K results for higher precision. Pair it with Qwen3-Embedding for a two-stage pipeline that typically adds 5-15% accuracy over embedding-only retrieval.
Embeds text, images, screenshots, and video into a unified vector space. #1 on MMEB-V2. Use this when your documents contain visual content — PDFs, slides, product images, video frames.
Cross-attention reranker for multimodal retrieval. Boosts accuracy on top of VL-Embedding the same way the text reranker improves text retrieval.
Bottom line: For most developers building text RAG, the Qwen3-Embedding-8B + Qwen3-Reranker-8B combo is the strongest open-source pipeline you can deploy today. If you're on a budget or targeting edge devices, the 0.6B variants still outperform many competitors at a fraction of the compute.
Qwen3-Embedding: Text Embedding Models
Three sizes, all sharing the same architecture and training pipeline. The difference is capacity and speed — pick based on your accuracy requirements and hardware budget.
| Model | Parameters | Max Tokens | Max Dimensions | MRL Support | Languages |
|---|---|---|---|---|---|
| Qwen3-Embedding-0.6B | 0.6B | 32,768 | 1,024 | Yes (32-1024) | 100+ natural, 100+ code |
| Qwen3-Embedding-4B | 4B | 32,768 | 2,560 | Yes (32-2560) | 100+ natural, 100+ code |
| Qwen3-Embedding-8B | 8B | 32,768 | 4,096 | Yes (32-4096) | 100+ natural, 100+ code |
MRL (Matryoshka Representation Learning) is the standout feature here. You can shrink the embedding dimension from 4,096 all the way down to 32 without retraining — just truncate the vector. At 256 dimensions you'll keep roughly 95% of the 8B's retrieval accuracy while cutting storage costs by 16x. That's a real production advantage when you're indexing millions of documents.
All three models are instruction-aware. You prepend a short task description to your query — something like "Retrieve documents about machine learning" — and the model adjusts its representation accordingly. This works significantly better than generic one-size-fits-all embeddings, especially for domain-specific retrieval.
Benchmark Performance
| Model | MTEB Multilingual | MTEB English v2 | MTEB Code | C-MTEB (Chinese) |
|---|---|---|---|---|
| Qwen3-Embedding-8B | 70.58 (#1) | 75.22 | 80.68 (#1) | 73.84 |
| Qwen3-Embedding-4B | ~69 | 74.60 | ~79 | — |
| Qwen3-Embedding-0.6B | ~66 | 70.70 | ~73 | — |
The 8B model holds the #1 spot on both MTEB Multilingual and MTEB Code. That code embedding score — 80.68 — matters if you're building code search, repository indexing, or developer tooling. The 0.6B is roughly 5 points behind the 8B across all benchmarks, which sounds like a lot until you realize it still beats most competing models that are 10x its size.
Qwen3-Embedding vs OpenAI, Cohere, and Gemini
This is where things get interesting. The embedding market has been dominated by closed-source APIs — OpenAI's text-embedding-3-large has been the default choice for most developers since early 2024. Qwen3-Embedding changes that equation.
| Model | MTEB Multilingual | Max Dimensions | Max Tokens | Open Source | Cost (API) |
|---|---|---|---|---|---|
| Qwen3-Embedding-8B | 70.58 | 4,096 | 32,768 | Yes (Apache 2.0) | Free locally / API available |
| Gemini Embedding | ~70+ | 768 | 8,192 | No | Google API pricing |
| Cohere embed-v4 | 65.2 | 768 | — | No | $0.10/1M tokens |
| OpenAI text-embedding-3-large | 64.6 | 3,072 | 8,191 | No | $0.13/1M tokens |
| OpenAI text-embedding-3-small | ~62 | 1,536 | 8,191 | No | $0.02/1M tokens |
Three advantages stand out. First, accuracy: the 8B scores nearly 6 points above OpenAI's best on MTEB Multilingual and over 5 above Cohere. On code embeddings specifically, the gap widens further. Second, context length: 32K tokens versus 8K means you can embed entire documents, long code files, or multi-page articles without chunking them into fragments that lose context. Third, cost: you can run it on your own hardware for zero marginal cost. At scale, that's the difference between a $500/month embedding bill and a one-time GPU investment.
The honest caveat: Gemini Embedding scores competitively on multilingual (roughly tied), and it doesn't require you to manage any infrastructure. If you want zero operational overhead and don't need the 32K context or code embedding capabilities, Gemini is a legitimate alternative. OpenAI's models, though, are now clearly behind on raw quality — their advantage is ecosystem lock-in and the convenience of staying in one API.
One more thing worth noting: because Qwen3-Embedding is open-source, you can fine-tune it on your domain data. None of the closed-source alternatives offer that. For specialized use cases — legal documents, medical records, proprietary code — fine-tuning typically adds 3-8 points on domain-specific retrieval benchmarks.
Qwen3-Reranker: Two-Stage Retrieval That Actually Works
Embedding models are fast but imprecise. They encode your query and documents independently, then compare them by vector similarity. A reranker is different — it takes a query-document pair and scores them jointly using cross-attention. Much slower, much more accurate.
The practical workflow: your embedding model retrieves the top 50-100 candidates quickly, then the reranker re-scores those candidates to produce a final top-10 or top-20. This two-stage approach gives you the speed of embedding search with the precision of cross-encoding.
| Model | MTEB Reranking | MTEB Code Reranking | Best For |
|---|---|---|---|
| Qwen3-Reranker-8B | Top tier | 81.22 | Maximum accuracy, production systems |
| Qwen3-Reranker-4B | 69.76 | — | Balance of speed and quality |
| Qwen3-Reranker-0.6B | 65.80 | — | Edge deployment, low latency |
| BGE-Reranker-m3 (0.6B) | 57.03 | — | Previous open-source standard |
The numbers here tell a stark story. Even the smallest Qwen3-Reranker (0.6B) beats BGE-m3's reranker by 8.77 points on MTEB Reranking and by over 32 points on code reranking. BGE-m3 was the default open-source reranker for most of 2024 and 2025 — Qwen3 makes it obsolete at every size.
Do you actually need a reranker? For prototypes and low-stakes search, embedding-only retrieval is fine. For production RAG where answer quality directly impacts your product, yes — the reranker is the single easiest upgrade you can make. Community reports consistently show 5-15% improvements in retrieval precision, and those gains compound when your LLM is generating answers from the retrieved context.
How to Build a RAG Pipeline with Qwen Embeddings
This is the section that matters most. Everything above was context — here's how you actually wire these models into a working retrieval system.
The Two-Stage Architecture
A production RAG pipeline with Qwen embeddings works in two phases:
- Indexing phase: Embed your documents with Qwen3-Embedding, store the vectors in a vector database (ChromaDB, Qdrant, Milvus, Pinecone — any will work).
- Query phase: Embed the user query, retrieve top-K candidates by vector similarity, rerank with Qwen3-Reranker, pass the top results to your LLM for answer generation.
Quick Start with Ollama
The fastest way to get Qwen embeddings running locally. No Python environment, no dependency management — just pull and go.
# Pull the embedding model
ollama pull qwen3-embedding
# Generate embeddings via CLI
curl http://localhost:11434/api/embed -d '{
"model": "qwen3-embedding",
"input": "What is retrieval-augmented generation?"
}'Ollama serves the model on a local HTTP endpoint. Any application that can make HTTP requests can use it — no SDK required. For the reranker, you'll need to use Sentence Transformers or Transformers directly, as Ollama doesn't support reranking natively yet.
Python with Sentence Transformers
from sentence_transformers import SentenceTransformer
# Load the model (downloads ~16GB for 8B on first run)
model = SentenceTransformer("Qwen/Qwen3-Embedding-8B")
# Embed documents
docs = [
"RAG combines retrieval with generation for grounded answers.",
"Vector databases store high-dimensional embeddings for fast search.",
"Fine-tuning adapts pre-trained models to domain-specific tasks."
]
doc_embeddings = model.encode(docs, prompt_name="document")
# Embed a query (note: different prompt for queries vs documents)
query = "How does RAG work?"
query_embedding = model.encode([query], prompt_name="query")
# Compute similarity
similarities = model.similarity(query_embedding, doc_embeddings)
print(similarities)
# The first document will score highestLangChain Integration
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.llms import Ollama
# Set up Qwen embeddings via Ollama
embeddings = OllamaEmbeddings(model="qwen3-embedding")
# Split and index your documents
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = splitter.split_documents(your_documents)
vectorstore = Chroma.from_documents(chunks, embeddings)
# Query with retrieval
retriever = vectorstore.as_retriever(search_kwargs={"k": 20})
results = retriever.invoke("How does Qwen handle multilingual input?")
# Pass to LLM for answer generation
llm = Ollama(model="qwen3:8b")
# ... chain the retriever with the LLM using your preferred LangChain chainAdding the Reranker Stage
from sentence_transformers import CrossEncoder
# Load reranker
reranker = CrossEncoder("Qwen/Qwen3-Reranker-8B")
# After retrieving top-K from vector search
query = "How does Qwen handle multilingual input?"
top_k_docs = [doc.page_content for doc in results] # from retriever above
# Score each query-document pair
pairs = [[query, doc] for doc in top_k_docs]
scores = reranker.predict(pairs)
# Sort by reranker score (highest first)
reranked = sorted(zip(scores, top_k_docs), reverse=True)
# Take top 5 for your LLM context
final_context = [doc for _, doc in reranked[:5]]This two-stage approach — retrieve 20-50 candidates with the embedding model, rerank to the top 5 — is what production systems at companies like Cohere and Pinecone recommend. The difference is you're doing it with fully open-source models at zero API cost.
For deploying Qwen models locally, check our full local setup guide. The embedding and reranker models work with every major serving framework — vLLM, Text Embeddings Inference (TEI), and Sentence Transformers all support them.
Qwen3-VL-Embedding: Multimodal Retrieval
Text embeddings only work when your data is text. The moment your corpus includes images, PDFs with charts, screenshots, or video, you need a multimodal embedding model. That's what Qwen3-VL-Embedding does — it maps text, images, visual documents, and video frames into the same vector space, so you can search across modalities.
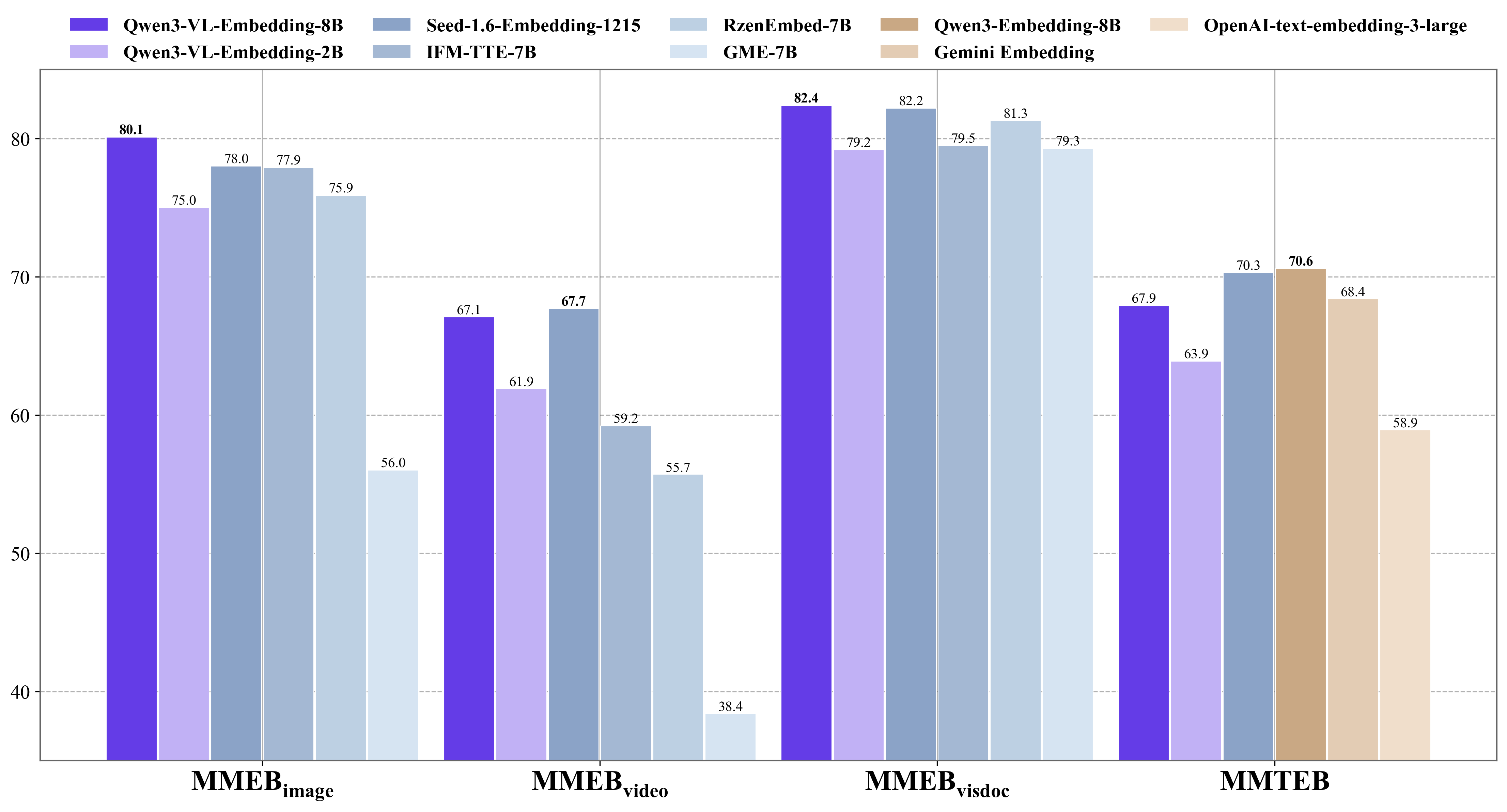
| Model | Parameters | MMEB-V2 Overall | Image | Video | VisDoc | Max Dims |
|---|---|---|---|---|---|---|
| Qwen3-VL-Embedding-8B | 8B | 77.9 (#1) | 80.1 | 66.1 | 83.3 | 4,096 |
| Qwen3-VL-Embedding-2B | 2B | 73.4 | 75.0 | 61.9 | 79.5 | 2,048 |
The 8B model holds the global #1 position on MMEB-V2. The VisDoc score of 83.3 is particularly important — that's the benchmark for retrieving visual documents like PDFs, slides, and screenshots. If you're building a system that needs to search through scanned invoices, research papers with figures, or product catalogs, this is the model to use.
A concrete use case: imagine you're building a support system for a hardware company. Customers upload photos of error screens, product labels, or damaged parts. VL-Embedding lets you embed those images alongside your text knowledge base, so a photo of a blinking LED pattern can retrieve the troubleshooting guide that matches it — without the customer needing to describe the problem in words.
Video retrieval is the weakest area, with a 66.1 score. That's still the best among open-source options, but it's notably lower than the image and document scores. If video search is your primary use case, expect to supplement the embedding retrieval with additional metadata filtering.
Qwen3-VL-Reranker: Precision for Multimodal Search
Same concept as the text reranker, applied to multimodal content. Qwen3-VL-Reranker uses single-tower cross-attention to jointly score a query against a multimodal document — meaning it can look at both the text query and the image/document simultaneously before assigning a relevance score.
Available in 2B and 8B sizes. The architecture shares the same Qwen3 Dense Decoder backbone with a vision encoder, so if you're already running VL-Embedding, adding the reranker doesn't require a fundamentally different infrastructure setup.
Use this when your multimodal retrieval needs to be precise — product search where showing the wrong item costs you a sale, medical image retrieval where accuracy is non-negotiable, or document search in regulated industries where returning the wrong document is a compliance risk.
Running Qwen Embeddings Locally
Five frameworks support Qwen3-Embedding, each with different tradeoffs:
| Framework | Best For | Setup Complexity |
|---|---|---|
| Ollama | Quick local setup, prototyping | Minimal |
| Sentence Transformers | Python integration, fine-tuning | Low |
| Transformers (HuggingFace) | Custom pipelines, research | Low |
| vLLM | High-throughput production serving | Medium |
| TEI (Text Embeddings Inference) | Production serving, Docker-native | Medium |
Performance Expectations
The 0.6B model runs comfortably on CPU — expect around 380ms per query on a modern processor, dropping to roughly 85ms on a T4 GPU. That's fast enough for real-time search in most applications. The accuracy tradeoff is about 5 points below the 8B, which sounds significant but still puts the 0.6B ahead of many competing models.
The 8B model needs a GPU. An RTX 3090 or 4090 with 24GB VRAM will handle it in FP16. For production throughput — hundreds of queries per second — you'll want an A100 or H100. If you're processing a large corpus offline (millions of documents at indexing time), vLLM with batching on an A100 is the recommended setup.
For checking whether your specific hardware can handle Qwen models, our Can I Run Qwen tool covers the full lineup including embedding models.
API Alternative: text-embedding-v4
If you don't want to manage infrastructure, Alibaba offers Qwen3-Embedding through the DashScope API as text-embedding-v4. It supports flexible dimensions (64-2048), 100+ languages, and batches of up to 10 texts at 8,192 tokens each. The API version has a shorter context window than the local model (8K vs 32K), so if you need the full 32K, you'll need to self-host.
For a full list of Qwen API models and their pricing tiers, check our API guide. The embedding API is significantly cheaper than the chat model APIs.
Frequently Asked Questions
Which Qwen3-Embedding size should I use?
8B for maximum retrieval quality — research, production search, anything where accuracy drives business value. 4B for a solid middle ground when you have GPU access but need faster throughput. 0.6B for edge deployment, CPU-only environments, or when you're embedding millions of documents and compute cost is the bottleneck. The 0.6B still outperforms OpenAI's text-embedding-3-small on multilingual benchmarks.
Are Qwen embeddings better than OpenAI's?
On MTEB benchmarks, yes — by a significant margin. Qwen3-Embedding-8B scores 70.58 on MTEB Multilingual versus 64.6 for OpenAI's text-embedding-3-large. It also handles 32K tokens versus 8K, and you can run it locally for free. The tradeoff: OpenAI's API is simpler to integrate if you're already in their ecosystem, and you don't need to manage any infrastructure. For most new projects, though, Qwen is the better technical choice.
Do I need the reranker, or is embedding-only enough?
For quick prototypes and internal tools, embedding-only search works well enough. For production systems where retrieval quality affects your product — customer-facing search, RAG-powered assistants, document retrieval — add the reranker. The 5-15% accuracy improvement from two-stage retrieval is one of the highest-ROI upgrades in any search pipeline. Start with embedding-only, measure your retrieval quality, then add reranking when you need to improve.
Can I use VL-Embedding for document search (PDFs, screenshots)?
Yes, and it's exceptionally good at it. The 8B model scores 83.3 on VisDoc — the highest of any model tested. It handles scanned documents, slides, screenshots, and PDFs with visual elements (charts, diagrams, tables) better than text-only approaches that rely on OCR. If your documents are mostly text, standard Qwen3-Embedding will be faster and cheaper. If they contain significant visual content, VL-Embedding is worth the extra compute.
How do Qwen embeddings compare to the Qwen 3 chat models?
Different purpose entirely. Qwen 3.5 and Qwen 3 are generative models — they produce text. Embedding models produce numerical vectors that represent meaning. You'd typically use both together: embeddings for retrieval, then a chat model like Qwen Max or Qwen 3.5 for generating the answer from the retrieved context. That's the RAG pattern described in the pipeline section above.