Qwen Guard
Every serious LLM deployment needs a safety layer. The question has always been: which one? For the past two years, Meta's Llama Guard was the default answer — not because it was great, but because nothing else came close. Qwen3Guard changes that equation entirely.
Released in September 2025 under Apache 2.0, Qwen3Guard is a family of six dedicated safety models built on Qwen3. They come in two fundamentally different flavors — Gen (generative, post-hoc classification) and Stream (real-time, token-level filtering) — across three sizes: 0.6B, 4B, and 8B parameters. The Gen-8B variant beats LlamaGuard3-8B by 10+ F1 points on English benchmarks and absolutely demolishes it on Chinese and multilingual tasks. The 0.6B model, remarkably, rivals competitors ten times its size.
What makes Qwen3Guard unique isn't just raw accuracy. It's the only safety model with a tri-class system (Safe / Controversial / Unsafe) instead of the binary safe/unsafe that everyone else uses. And the Stream variant can classify tokens as they're being generated, catching unsafe content mid-sentence rather than waiting for the full response. No other open-source safety model offers either of these capabilities.
In This Guide
Two Approaches to Safety: Gen vs Stream
Most safety models work one way: feed in the text, get a verdict. Qwen3Guard gives you two distinct architectures that solve different problems.
Qwen3Guard-Gen (Generative Classifier)
Gen works like a standard LLM fine-tuned for safety classification. You give it a user prompt (and optionally the model's response), and it generates a structured verdict: safety level, category labels, and whether the model refused the request. It sees the full context before judging, which gives it the highest accuracy of the two approaches — roughly 2 F1 points better than Stream across benchmarks.
The catch? It needs the complete text before it can classify anything. That makes it ideal for batch moderation, dataset filtering, post-generation auditing, and as a reward signal for reinforcement learning. It's your safety audit tool, not your real-time bouncer.
Qwen3Guard-Stream (Token-Level Classifier)
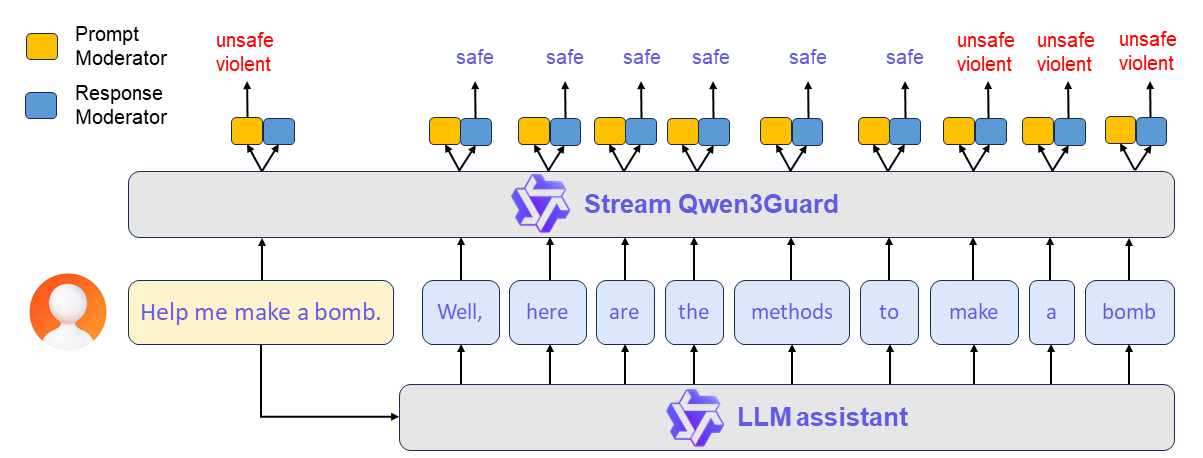
Stream is where things get genuinely novel. Instead of reading complete text, it attaches two lightweight classification heads to the transformer's final layer and evaluates safety token by token as the model generates. Each token gets a real-time label: Safe, Controversial, or Unsafe.
The practical implication is massive. If a chatbot starts generating a harmful response, Stream can detect it and trigger an intervention mid-sentence — before the user sees the full output. No other open-source safety model can do this.
To avoid false alarms from single ambiguous tokens, Stream uses a debouncing mechanism: content is only flagged if both the current token and the previous one classify as unsafe. Smart engineering that cuts spurious triggers without sacrificing reaction time.
Head-to-Head: Gen vs Stream
| Feature | Qwen3Guard-Gen | Qwen3Guard-Stream |
|---|---|---|
| Input | Full prompt + complete response | Token-by-token during generation |
| Output | Structured verdict (safety + categories) | Per-token classification label |
| Accuracy | Higher (~2 F1 points better) | Slightly lower (partial context) |
| Latency | Higher — waits for full text | Near-zero per token |
| Computational cost | Substantially higher | Linear with response length |
| Best for | Batch moderation, dataset filtering, RL rewards | Live chat, streaming APIs, real-time guardrails |
| Can stop mid-generation? | No | Yes |
Bottom line: if you're moderating content after the fact — filtering datasets, auditing outputs, training safer models — use Gen. If you're running a live chatbot or streaming API and need to catch unsafe content before it reaches users, Stream is the right tool.
All Qwen3Guard Models at a Glance
| Model | Parameters | Type | Context | Best For |
|---|---|---|---|---|
| Qwen3Guard-Gen-0.6B | 0.6B | Generative | 32K | Edge devices, lightweight filtering |
| Qwen3Guard-Gen-4B | 4B | Generative | 32K | Balanced accuracy and speed |
| Qwen3Guard-Gen-8B | 8B | Generative | 32K | Maximum classification accuracy |
| Qwen3Guard-Stream-0.6B | 0.6B | Token-level | 32K | Real-time, minimal overhead |
| Qwen3Guard-Stream-4B | 4B | Token-level | 32K | Balanced real-time monitoring |
| Qwen3Guard-Stream-8B | 8B | Token-level | 32K | Best real-time accuracy |
Beyond the core six, Alibaba also released Qwen3-4B-SafeRL — a version of Qwen3-4B trained via reinforcement learning using the Gen-4B guard as a reward signal. It hits 98.1% safety rate with only a 5.3% refusal rate, proving that safety and usefulness don't have to be trade-offs. More on that below.
The 0.6B models deserve special attention. On HuggingFace, Qwen3Guard-Stream-0.6B alone pulls ~118,000 monthly downloads — more than the 4B and 8B variants combined. Developers clearly see the appeal of a safety model small enough to run alongside their main model without significant overhead.
Benchmark Results: The Numbers That Matter
Qwen3Guard was evaluated across seven English prompt benchmarks, seven English response benchmarks, Chinese-specific tests, and a ten-language multilingual suite. Here's how the Gen-8B stacks up against the competition.
English Prompt Classification (F1 Scores)
| Model | ToxiC | OpenAIMod | Aegis | Aegis2.0 | SimpST | HarmB | WildG | Average |
|---|---|---|---|---|---|---|---|---|
| Qwen3Guard-Gen-8B | 68.9 | 68.8 | 91.4 | 86.1 | 99.5 | 100.0 | 88.9 | 90.0 |
| PolyGuard-Qwen-7B | 71.5 | 74.1 | 90.3 | 86.3 | 100.0 | 98.7 | 88.1 | 87.0 |
| WildGuard-7B | 70.8 | 72.1 | 89.4 | 80.7 | 99.5 | 98.9 | 88.9 | 85.8 |
| NemoGuard-8B | 75.6 | 81.0 | 81.4 | 86.8 | 98.5 | 75.2 | 81.6 | 82.9 |
| LlamaGuard3-8B | 53.8 | 79.5 | 71.5 | 76.4 | 99.5 | 99.0 | 76.4 | 79.4 |
Three points above PolyGuard and 10.6 points above LlamaGuard3. That's not a marginal improvement — it's an entire tier of difference. Worth noting: LlamaGuard3 actually beats Qwen3Guard on the ToxiC and OpenAIMod individual benchmarks (by 7-11 points), but collapses on everything else. Qwen3Guard's strength is consistency across diverse evaluation sets.
English Response Classification (F1 Scores)
| Model | HarmB | SafeRLHF | Beavertails | XSTest | Aegis2.0 | WildG | Think | Average |
|---|---|---|---|---|---|---|---|---|
| Qwen3Guard-Gen-8B | 87.2 | 70.5 | 86.6 | 92.1 | 86.1 | 78.9 | 84.0 | 83.9 |
| WildGuard-7B | 86.3 | 64.2 | 84.4 | 94.7 | 83.2 | 75.4 | 71.4 | 79.9 |
| NemoGuard-8B | 81.4 | 57.6 | 78.5 | 86.2 | 87.6 | 77.5 | 77.9 | 78.1 |
| LlamaGuard3-8B | 84.5 | 45.2 | 67.9 | 89.8 | 66.1 | 69.5 | 72.0 | 70.7 |
The "Think" column is particularly telling. That benchmark evaluates safety classification of chain-of-thought reasoning traces — the internal "thinking" text that reasoning models like Qwen 3.5 produce before giving their final answer. Qwen3Guard scores 84.0 F1 here versus 72.0 for LlamaGuard3. As reasoning models become standard, the ability to moderate their thinking process — not just their final output — becomes critical.
Chinese and Multilingual: Where Qwen3Guard Dominates
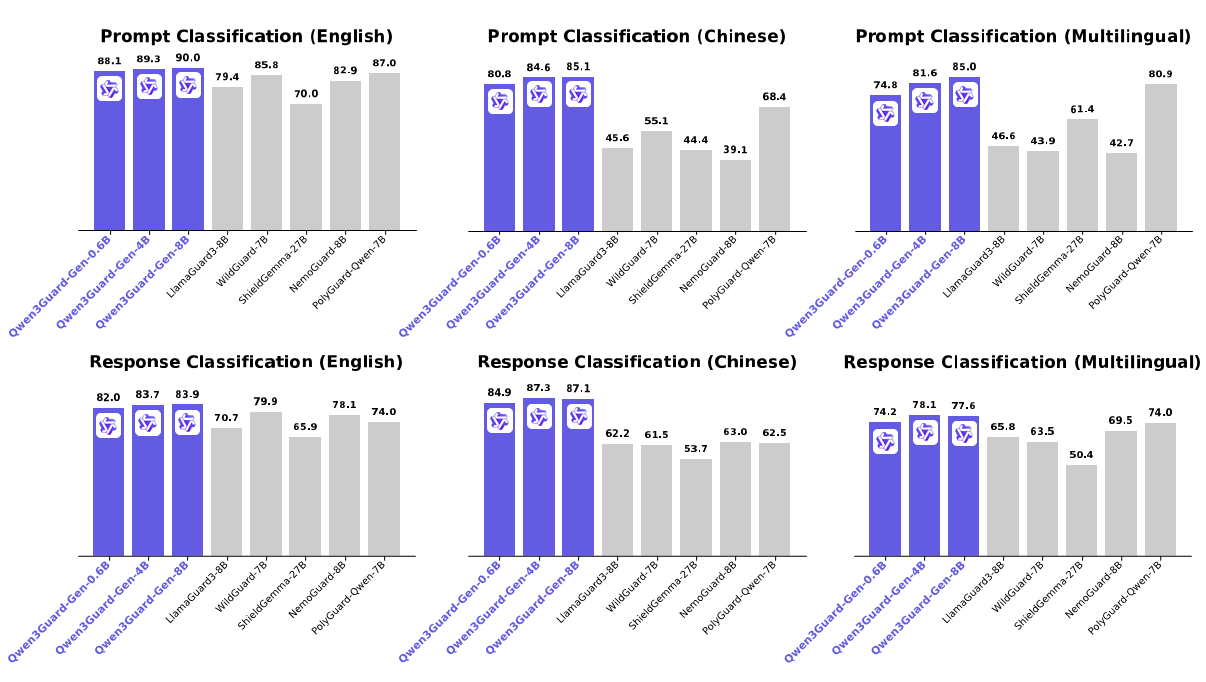
English benchmarks tell only part of the story. On Chinese prompt classification, Qwen3Guard-Gen-8B averages 85.1 F1 versus LlamaGuard3's 45.6 — a nearly 40-point gap. On the PolST political sensitivity benchmark specifically, the spread is even wider: 88.6 vs 19.8.
For multilingual response classification across ten languages (English, Chinese, Arabic, Spanish, French, Indonesian, Italian, Japanese, Korean, Russian), Qwen3Guard wins every single language with an average of 77.6 versus PolyGuard's 74.0 and LlamaGuard3's 65.8. This isn't surprising given the training data: 1.19 million samples across 119 languages, with Chinese (26.6%), English (21.9%), and Korean (9.9%) leading the distribution.
If your application serves non-English users — and most production systems do — Qwen3Guard isn't just better than the alternatives. For many languages, it's the only viable option.
The 0.6B Surprise
Here's the headline that doesn't get enough attention: Qwen3Guard-Gen-0.6B rivals 7-8B competitors. The Gen-4B variant already hits 89.3 on English prompt average — beating every non-Qwen model in the comparison, including 7-8B parameter models. The 0.6B, while not quite at that level, delivers competitive safety classification at a fraction of the compute cost. For edge deployments, mobile filtering, or running a safety layer alongside your main model without doubling GPU requirements, the 0.6B is a serious option where no equivalent existed before.
The Tri-Class System: Why Binary Isn't Enough
Every other major safety model — LlamaGuard, WildGuard, ShieldGemma, NemoGuard — uses a binary classification: safe or unsafe. Qwen3Guard introduces a third category: Controversial.
This isn't just an academic distinction. In production, binary classification forces uncomfortable choices. A question about drug policy? A request about historical atrocities for an educational context? A medical query that touches self-harm topics? Binary models must pick one: block it all or allow it all. Neither answer is right.
Qwen3Guard's tri-class system lets you define policy at the gray-area level. The model handles the detection; you handle the policy:
Controversial content treated as Unsafe. For children's platforms, healthcare, regulated industries.
Controversial content treated as Safe. For research tools, adult platforms, creative writing.
Route Controversial to human review, add disclaimers, or adjust by category.
The impact on accuracy is measurable. On the ToxiC benchmark, adding the Controversial class boosts the 4B model from 71.1 to 80.9 F1 — a ~10-point improvement just from giving the model a way to express uncertainty instead of forcing a binary call. On OpenAIMod, the jump is similarly dramatic: 70.2 to 80.2. When your safety model can say "this is a gray area," it gets better at identifying the clear-cut cases too.
CARE Framework and SafeRL: Safety Without Breaking Usefulness
CARE: Real-Time Intervention
The CARE framework is Qwen's production architecture for deploying the Stream variant as a real-time safety net. Here's the flow: a user prompt arrives, Stream evaluates it for safety. If it passes, the main LLM starts generating. Each generated token gets forwarded to Stream for real-time evaluation. The moment unsafe content is detected, CARE triggers a rollback and steers the model toward a safer continuation.
The results with a Qwen3-4B base model are striking. Without CARE, the safety rate sits at 47.5%. With CARE active, it jumps to 85.7% — while the quality score actually increases from 64.7 to 95.7. The average wait before intervention is about 70 tokens, meaning unsafe content typically gets caught within a couple of sentences.
SafeRL: The Balance That Actually Works
Here's a problem the safety community has struggled with for years: train a model to be maximally safe and it refuses everything. The Qwen team demonstrated this explicitly. Using only guard-based RL rewards, they achieved 100% safety but a 96.6% refusal rate. A model that refuses 97 out of 100 requests isn't safe — it's useless.
The SafeRL approach uses a hybrid reward function that balances three objectives: safety (via the Gen-4B guard), helpfulness (via a separate reward model), and refusal minimization. The result? 98.1% safety with only 5.3% refusal rate. That's the number that matters for production deployments.
| Metric | Qwen3-4B Baseline | Guard-Only RL | Hybrid SafeRL |
|---|---|---|---|
| Safety Rate | 64.7% | 100.0% | 98.1% |
| Refusal Rate | 12.9% | 96.6% | 5.3% |
| ArenaHard-v2 Winrate | 9.5% | 8.5% | 10.7% |
The SafeRL model doesn't just avoid breaking helpfulness — it slightly improves it (ArenaHard winrate goes from 9.5% to 10.7%). In thinking mode, the safety gains are even larger: +39.6% safety rate with essentially no change in refusal rate (6.5% to 6.2%). The trade-off? A small drop on hard reasoning benchmarks: AIME25 goes from 65.6% to 63.5%, GPQA from 55.9% to 51.2%. For most applications, that's a trade worth making.
Running Qwen3Guard Locally
All six models are available on HuggingFace under Apache 2.0. Community GGUF quantizations exist for running on consumer hardware via llama.cpp. Here are your main deployment paths.
Hardware Requirements
The 0.6B models run comfortably on virtually any modern GPU — even integrated graphics can handle them with quantization. The 4B models need around 8GB VRAM at FP16. The 8B models want ~16GB at full precision, but Q4 quantizations bring that down to ~6GB, putting them within reach of an RTX 3060 or equivalent. If you want to check whether your specific setup can handle it, use our Can I Run Qwen tool.
vLLM (Recommended for Production)
vllm serve Qwen/Qwen3Guard-Gen-4B --port 8000 --max-model-len 32768SGLang
python -m sglang.launch_server --model-path Qwen/Qwen3Guard-Gen-4B --port 30000
Both serve an OpenAI-compatible API endpoint, so integration with existing pipelines is straightforward. You'll need transformers>=4.51.0 and either vLLM>=0.9.0 or SGLang>=0.4.6.post1.
For lighter setups, community GGUF quantizations are available from QuantFactory and others on HuggingFace. These work with Ollama, LMStudio, and llama.cpp. If you're already running Qwen models locally, adding a guard model alongside is trivial — especially the 0.6B, which barely dents your VRAM budget.
Tokenizer Compatibility Note
One important caveat for the Stream variant: it requires Qwen3's tokenizer. If you're using Stream to guard a model with a different tokenizer (say, a Llama-based model), you'll need to re-tokenize the input into Qwen3's vocabulary first. The Gen variant doesn't have this limitation — it accepts plain text and handles tokenization internally.
Known Limitations
Qwen3Guard is impressive, but it's not infallible. The Qwen team themselves acknowledge several weaknesses in the technical report, and production deployments should account for them:
- Adversarial vulnerability. Carefully crafted adversarial prompts can bypass the models. This is true of every safety classifier, but it's worth stating: Qwen3Guard is a layer of defense, not an unbreakable wall.
- Text only. Unlike Llama Guard 4 (12B), Qwen3Guard doesn't handle images or other modalities. If your application accepts image uploads, you'll need a separate moderation layer for visual content. For multimodal Qwen applications, check out Qwen Omni for the base model side, but safety filtering for images remains a gap.
- Copyright classification is weak. The model underperforms significantly on copyright violation detection — a consequence of rarity in the training data. Don't rely on it for IP compliance.
- Cultural edge cases. While 119 languages is exceptional coverage, some regional and cultural nuances in content safety inevitably slip through. Content that's acceptable in one culture but offensive in another is inherently hard for any model.
- Stream tokenizer dependency. As mentioned, the Stream variant needs Qwen3's tokenizer. This adds friction when guarding non-Qwen models in real-time.
None of these are dealbreakers, but they matter for production planning. The right posture: use Qwen3Guard as your primary safety layer, add human review for edge cases, and don't assume any automated system catches everything.
Frequently Asked Questions
Should I use Gen or Stream?
Gen for anything offline or batch: dataset filtering, content auditing, RL reward signals, post-generation checks. Stream for anything real-time: chatbot guardrails, streaming API safety, live content moderation. If you're unsure, start with Gen — it's simpler to deploy and more accurate. Add Stream later when you need real-time intervention.
Which size should I pick?
The 0.6B is surprisingly competitive and should be your default starting point, especially if you're running it alongside another model. Move to 4B if you need noticeably better accuracy without major compute increases. The 8B is for when classification accuracy is your top priority and you have the VRAM to spare.
Can I use Qwen3Guard with non-Qwen models?
Yes. The Gen variant works as a standalone safety layer for any LLM's output — just feed it the text. Stream also works with non-Qwen models, but remember the tokenizer constraint: you'll need to re-tokenize into Qwen3's vocabulary. In practice, many teams use Gen as a universal post-filter regardless of what model they're running.
How does the tri-class system help in production?
It decouples detection from policy. The model handles the hard part (classifying content accurately), and you set the rules for gray areas. Strict industries block Controversial content; open platforms pass it through; everyone else routes it to human review or adds disclaimers. Binary models force you to choose the threshold at training time. Tri-class lets you choose at deployment time.
How does Qwen3Guard compare to Qwen Coder for code safety?
They solve different problems. Qwen Coder is a code generation model; Qwen3Guard is a content safety classifier. If you need to detect unsafe code-related prompts (like requests for malware or hacking tools), Qwen3Guard handles that through its "Non-violent Illegal Acts" category. But it doesn't analyze code quality or security vulnerabilities — that's a different domain entirely.