Qwen Image
Alibaba's image generation lineup just got its biggest upgrade. Qwen-Image 2.0, released on February 10, 2026, is a 7-billion-parameter model that handles both image generation and editing in a single architecture — something its predecessor needed two separate 20B models to do. It renders text on images better than anything else available right now, generates natively at 2K resolution, and ranked #1 on AI Arena for both text-to-image and image editing at launch.
There's a catch, though. Image 2.0 is API-only as of March 2026 — no open weights yet. If you want to run Qwen's image models locally, you'll need the v1 series (all open-weight under Apache 2.0), which we cover below alongside the full timeline from v1 to v2.

In this guide:
- What Changed in Image 2.0
- Text Rendering — The Standout Feature
- Benchmarks and Arena Rankings
- Image 2.0 vs GPT Image, Midjourney, and FLUX
- Full Timeline: From 20B to 7B Unified
- API Access and Pricing
- Running Qwen-Image Locally
- Quick-Start Code (Open-Weight v1)
- FAQ
What Changed in Image 2.0
The headline number: 65% fewer parameters. Qwen-Image 2.0 is a 7B model. Its predecessor was 20B. Normally, shrinking a model that aggressively means losing capability. Not here — Image 2.0 outperforms the entire v1 series on every benchmark Alibaba published, and the community's blind Arena evaluations back that up.
How? The architecture got a fundamental redesign. An 8B Qwen3-VL encoder handles prompt understanding and image comprehension, feeding into a 7B MMDiT (Multimodal Diffusion Transformer) decoder that generates output at up to 2048x2048 native resolution. The encoder does double duty — it processes text prompts for generation and understands existing images for editing, which is what allows one model to replace two.
| Spec | Image 2.0 (Feb 2026) | v1 Series (Aug 2024 - Dec 2025) |
|---|---|---|
| Parameters | 7B | 20B |
| Tasks | Generation + Editing (unified) | Separate models for each |
| Max Resolution | 2048x2048 native | ~1328x1328 |
| Max Prompt | 1,000 tokens | ~256 tokens |
| Text Rendering | Professional bilingual (EN + ZH) | Good, English-focused |
| Aspect Ratios | 1:1, 16:9, 9:16, 4:3, 3:4, 3:2, 2:3 | Limited |
| Open Weights | Not yet (API-only) | Apache 2.0 |
The prompt length jump matters more than it sounds. At 1,000 tokens, you can describe a full infographic layout, a multi-panel comic with dialog, or a poster with specific text placement instructions. Most competing models cap out at 77 tokens (Stable Diffusion) or 256 tokens — which forces you to compress your creative direction into a few short phrases.
Text Rendering — The Standout Feature
Every image generation model struggles with text. Letters come out backwards, words get misspelled, fonts look inconsistent. It's been the most stubborn problem in the field since DALL-E 1.
Qwen-Image 2.0 doesn't just improve text rendering — it makes it usable for production work. The model generates PowerPoint slides with accurate timelines and charts. It creates posters with mixed font sizes, weights, and colors that are correctly spelled. It handles Chinese calligraphy, including classical styles like Emperor Huizong's "Slender Gold Script," with only a handful of character errors across entire passages.

That's not a cherry-picked demo. The model consistently places text on 3D surfaces — glass, curved bottles, fabric — with correct perspective, reflections, and lighting. For e-commerce (product shots with pricing overlays), marketing (social media graphics), and content creation (infographics, presentation visuals), this is the feature that makes Image 2.0 genuinely practical rather than just impressive.
GPT Image 1.5 has improved its text rendering significantly, but community consensus on AI Arena puts Qwen-Image 2.0 ahead on multilingual text accuracy — particularly for mixed English-Chinese content. Midjourney still doesn't handle text well at all.
Benchmarks and Arena Rankings
Two types of evidence here: automated benchmarks (which Alibaba published) and blind human evaluations on AI Arena (which are independent and harder to game).
AI Arena — Blind Human Evaluation
AI Arena runs ELO-rated blind comparisons where judges see two images side-by-side without knowing which model made which. At launch, Qwen-Image 2.0 hit #1 on both the text-to-image and image editing leaderboards. As of March 2026, the rankings have shifted with newer entrants:
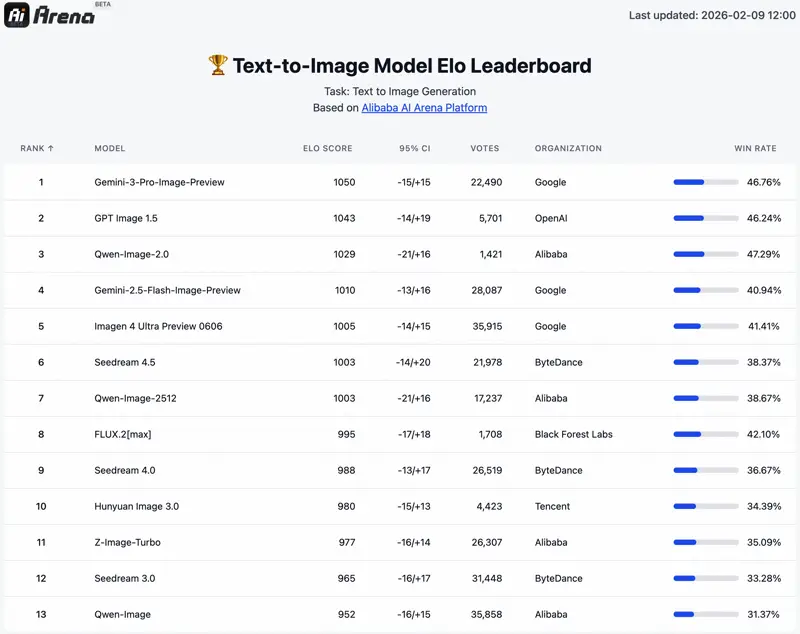
| Task | Image 2.0 Rank | Beats | Behind |
|---|---|---|---|
| Text-to-Image | #3 (ELO 1029) | Gemini 2.5 Flash, Imagen 4, Seedream 4.5, FLUX.2 | Gemini 3 Pro (1050), GPT Image 1.5 (1043) |
| Image Editing | #2 (ELO 1034) | Seedream 4.5, Qwen-Image-Edit-2511, FLUX.2 | Gemini 3 Pro (1042) |
Honest take: #3 on T2I and #2 on editing is excellent for a 7B model — GPT Image 1.5 and Gemini 3 Pro are both closed-source with unknown (likely much larger) parameter counts. But it's no longer the undisputed #1 it was at launch. If raw generation quality is your only priority and you don't care about open weights or cost, GPT Image 1.5 currently edges it out on Arena scores.
Automated Benchmarks
| Benchmark | Qwen-Image 2.0 | GPT Image 1 | FLUX.1 (12B) |
|---|---|---|---|
| GenEval | 0.91 | -- | -- |
| DPG-Bench | 88.32 | 85.15 | 83.84 |
DPG-Bench measures how faithfully a model follows prompts. Image 2.0's 88.32 beats GPT Image 1 by 3.17 points and FLUX.1 by 4.48. The long prompt support (1,000 tokens) likely helps here — when you can describe what you want in detail, the model has more to work with.
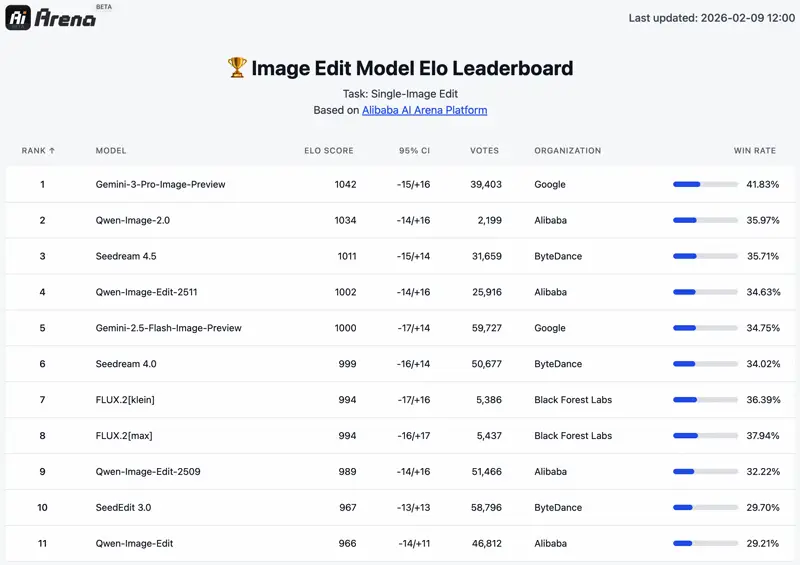
Image 2.0 vs GPT Image, Midjourney, and FLUX
The image generation space is crowded in 2026. Here's how Image 2.0 stacks up against the models people actually compare it to:
| Feature | Qwen-Image 2.0 | GPT Image 1.5 | Midjourney v7 | FLUX.2 Pro |
|---|---|---|---|---|
| Best at | Text rendering, bilingual | Complex instructions | Artistic style | Photographic accuracy |
| Parameters | 7B | Undisclosed | Undisclosed | ~12B |
| Gen + Edit unified | Yes | Yes | No | No |
| Max resolution | 2K native | 2K+ | 2K | 2K |
| Open weights | No (v1 series: yes) | No | No | Partial |
| Local deployment | v1 only (~24GB VRAM) | No | No | Yes |
| Price per image | $0.035 - $0.075 | ~$0.04 - $0.17 | Subscription | $0.04 - $0.06 |
Pick Qwen-Image 2.0 if: you need accurate text on images (especially bilingual), want the cheapest API pricing for production volume, or need unified generation and editing. It's the strongest option for e-commerce, marketing materials, and anything involving typography.
Pick GPT Image 1.5 if: you need the highest raw quality for complex, multi-element scenes and don't mind the cost. It handles intricate compositional prompts better than anything else right now.
Pick Midjourney if: artistic style is what matters most. For illustration, concept art, and aesthetic-driven work, Midjourney's output still has a distinctive quality that other models don't match. It doesn't do editing at all, though.
Pick FLUX if: you want open weights and photographic realism. FLUX.2 Pro produces extremely accurate photos, and you can run the base models locally. But it needs separate models for editing and doesn't handle text rendering well.
Full Timeline: From 20B to 7B Unified
Qwen's image generation story isn't just "v1 then v2." Between August 2024 and February 2026, Alibaba released seven distinct models, each iterating on specific weaknesses. The trajectory tells you where this is heading.
| Date | Model | Size | What It Added | Open Weights |
|---|---|---|---|---|
| Aug 2024 | Qwen-Image | 20B | First release. Text-to-image only. | Apache 2.0 |
| Aug 2025 | Qwen-Image-Edit | 20B | Dedicated editing model. Text rendering improvements. | Apache 2.0 |
| Sep 2025 | Edit-2509 | 20B | Identity preservation, multi-image editing. | Apache 2.0 |
| Dec 2025 | Edit-2511 | 20B | Less drift between edits, LoRA support, character consistency. | Apache 2.0 |
| Dec 2025 | Qwen-Image-2512 | 20B | Realistic humans, improved text rendering. | Apache 2.0 |
| Dec 2025 | Qwen-Image-Layered | 20B | Layered image decomposition (foreground/background). | Apache 2.0 |
| Feb 2026 | Qwen-Image 2.0 | 7B | Unified gen+edit, 2K native, 1000-token prompts. | API-only |
A few things stand out. First, the December 2025 burst — three specialized models in one month — reads like a final push to squeeze everything out of the 20B architecture before the 2.0 rewrite. Second, every v1 model is open-weight under Apache 2.0, meaning you can still run and fine-tune them today. Third, Image 2.0 broke that open pattern. Whether that's temporary (Alibaba has historically released weights within a month or two) or a strategic shift remains to be seen.
For most users, the practical takeaway is clear: Qwen-Image-2512 (December 2025) is the best open-weight option you can run today. Image 2.0 is better, but you'll need to use the API.
API Access and Pricing
Image 2.0 is available through Alibaba Cloud's DashScope platform and through Qwen Chat for free (with rate limits). Here's what the API costs:
| Model | Price per Image | Notes |
|---|---|---|
| qwen-image-2.0-pro | $0.075 | Highest quality tier |
| qwen-image-2.0 | $0.035 | Standard quality, best value |
| qwen-image-max (v1) | $0.075 | Legacy, open-weight equivalent available |
| qwen-image-plus (v1) | $0.03 | Legacy, cheapest option |
At $0.035 per image, the standard Image 2.0 tier undercuts most competitors for comparable quality. GPT Image 1.5 runs $0.04-$0.17 depending on resolution and complexity. FLUX.2 Pro is $0.04-$0.06 per image. For high-volume production use cases — generating thousands of product images or marketing variants — the cost difference adds up fast.
Third-party providers like Replicate and Fal.ai also host the v1 open-weight models if you want an alternative to DashScope.
Running Qwen-Image Locally
Image 2.0: API-only as of March 2026. No local deployment possible yet.
The v1 open-weight models — particularly Qwen-Image-2512 — are your best bet for local use. They're all Apache 2.0, available on Hugging Face and ModelScope, and work with HF Diffusers.
Hardware You'll Need
| Setup | VRAM | Example GPUs |
|---|---|---|
| Full precision (BF16) | ~24GB | RTX 4090, A6000 |
| FP8 quantized | ~12-16GB | RTX 4070 Ti Super, RTX 3090 |
| Layer-by-layer offload | 4GB+ | Any GPU (slow, but functional) |
DiffSynth-Studio is the recommended deployment tool — it handles low-VRAM offloading, FP8 quantization, and LoRA fine-tuning. For inference speed, Qwen-Image-Lightning with LightX2V acceleration achieves a reported ~42x speedup, though that requires more VRAM headroom.
Check our Can I Run Qwen? tool to see if your GPU handles the v1 models, and our local deployment guide for step-by-step setup.
Quick-Start Code (Open-Weight v1)
These examples use the open-weight v1 models — the ones you can actually run today. When Image 2.0 weights drop, the pipeline should be similar.
Text-to-Image with Qwen-Image-2512
from diffusers import QwenImagePipeline
import torch
pipe = QwenImagePipeline.from_pretrained(
"Qwen/Qwen-Image-2512",
torch_dtype=torch.bfloat16
).to("cuda")
image = pipe(
prompt="A professional infographic about renewable energy trends in 2026, clean modern design with charts and data visualizations",
negative_prompt="blurry, low quality, distorted text",
width=1664,
height=928,
num_inference_steps=50,
true_cfg_scale=4.0,
generator=torch.Generator(device="cuda").manual_seed(42)
).images[0]
image.save("output.png")Image Editing with Qwen-Image-Edit-2511
from diffusers import QwenImageEditPlusPipeline
from PIL import Image
import torch
pipeline = QwenImageEditPlusPipeline.from_pretrained(
"Qwen/Qwen-Image-Edit-2511",
torch_dtype=torch.bfloat16
).to("cuda")
source = Image.open("photo.jpg")
result = pipeline(
image=[source],
prompt="Change the background to a sunset beach scene",
num_inference_steps=40,
true_cfg_scale=4.0,
guidance_scale=1.0
).images[0]
result.save("edited.png")
Requirements: transformers >= 4.51.3 and latest diffusers from source (pip install git+https://github.com/huggingface/diffusers).
Sample Generations
A selection of Image 2.0 outputs across different styles and subjects:






Community and Ecosystem
The v1 open-weight models have built a solid ecosystem since August 2024: 7,400+ GitHub stars, 429 forks, and 484+ community LoRA adapters on Hugging Face covering everything from portrait enhancement to specific art styles. ComfyUI has native support, and multi-hardware inference (NVIDIA, Ascend, Cambricon) is available through LightX2V.
That ecosystem is a genuine advantage. When (or if) Image 2.0 goes open-weight, it'll inherit tooling and community infrastructure that took 18 months to build. Competing open models like FLUX had to build theirs from scratch.
For context on how Qwen-Image fits into the broader Qwen ecosystem: Qwen 3.5 handles image understanding (analyzing photos, documents, video), while Qwen-Image handles creation. Qwen3-Omni combines vision, audio, and text understanding in a single model. They're complementary — use the right tool for the job.
Frequently Asked Questions
Is Qwen-Image 2.0 open source?
Not yet. As of March 2026, Image 2.0 is API-only through Alibaba Cloud's DashScope platform. The previous v1 series (Qwen-Image, Qwen-Image-Edit, Qwen-Image-2512, etc.) are all fully open under Apache 2.0. Given the 7B parameter count — small enough for consumer GPUs — community expectation is that weights will eventually be released. But there's no confirmed timeline.
Can I run it on my own GPU?
Image 2.0 specifically, no — API-only for now. The v1 open-weight models run locally on 24GB+ VRAM at full precision, or as low as 4GB with layer-by-layer offloading (much slower). Qwen-Image-2512 is the strongest v1 model for local use. Check our hardware compatibility tool for your specific GPU.
How does Qwen-Image compare to Midjourney?
Different strengths. Qwen-Image 2.0 is substantially better at text rendering and offers unified editing capabilities that Midjourney doesn't have at all. Midjourney produces more distinctive artistic output and has a more refined aesthetic for illustration-style work. For commercial/production use (product images, marketing, infographics), Qwen-Image 2.0 is the stronger choice. For creative/artistic work, Midjourney still has an edge.
What's the difference between Qwen-Image and Qwen 3.5's vision features?
Qwen 3.5 understands images — it can describe them, extract text, answer questions about visual content. Qwen-Image creates images from text prompts and edits existing ones. One reads, the other writes. Use Qwen 3.5 when you need to analyze visual content, and Qwen-Image when you need to generate it.
Will Image 2.0 weights be released?
Alibaba hasn't confirmed anything. They've historically released weights for all Qwen-Image models within 1-2 months of the API launch, and the 7B size is well-suited for open release. But until it's announced, it's speculation. The v1 models are available right now if you need local deployment today.
Updated March 2026