Qwen Math
A 7-billion parameter model that outscores Llama-3.1-405B on the MATH benchmark. Read that again: 7B beating 405B. Qwen2.5-Math pulls this off by combining a math-only training pipeline with Tool-Integrated Reasoning (TIR) — a feature that lets the model write and execute Python code mid-problem to verify its own calculations. The result is a family of three specialized models (1.5B, 7B, 72B) released in September 2024 under Apache 2.0 that redefine what small math-focused LLMs can do.
This isn't a general-purpose model that happens to do math. It's the opposite: a model trained exclusively on mathematical data, optimized with a dedicated reward model, and built to solve problems from grade school arithmetic to competition-level AIME challenges. If you need raw mathematical horsepower in a package that fits on a single consumer GPU, this is where you start.
Qwen2.5-Math Models and Benchmarks
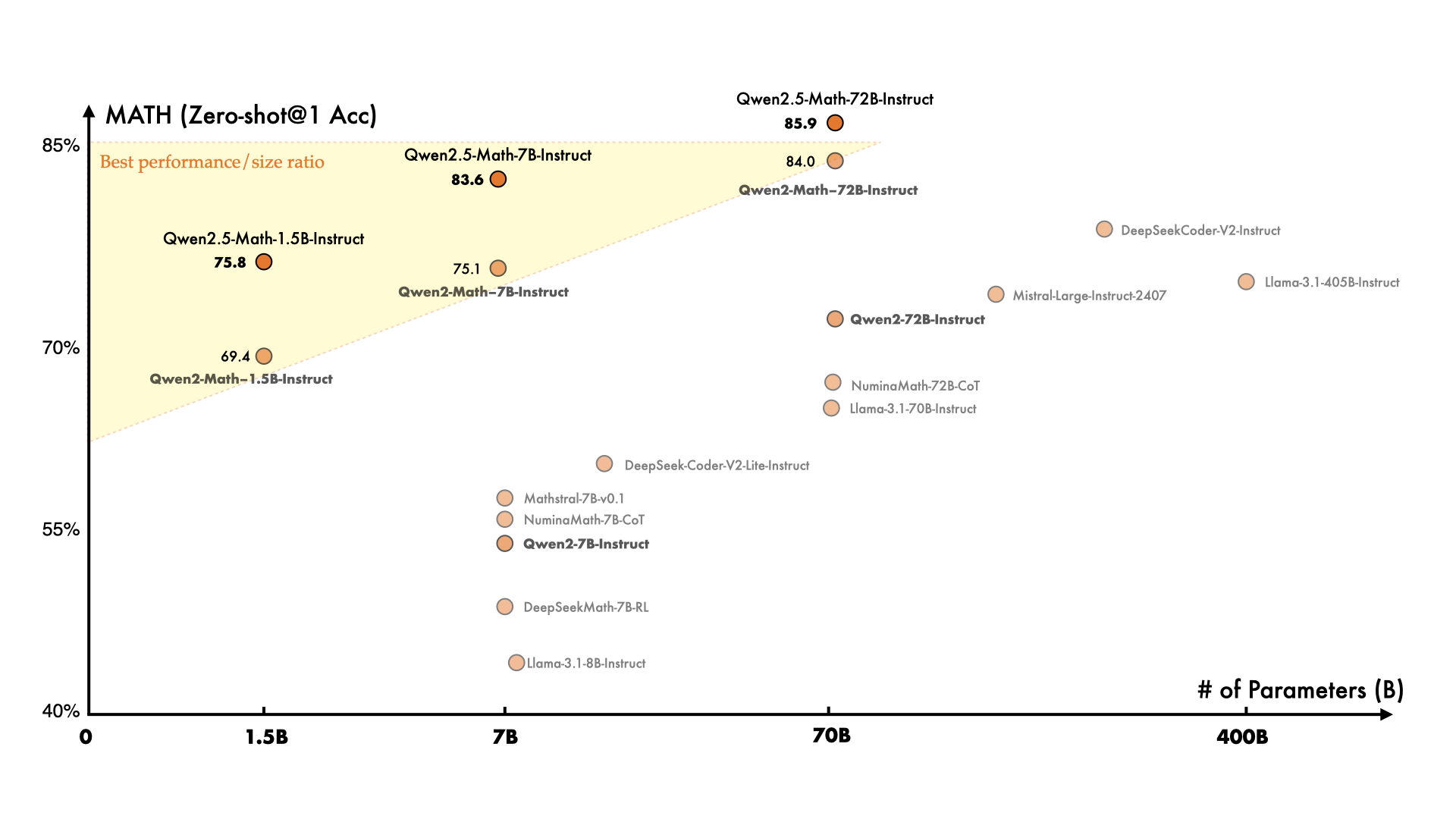
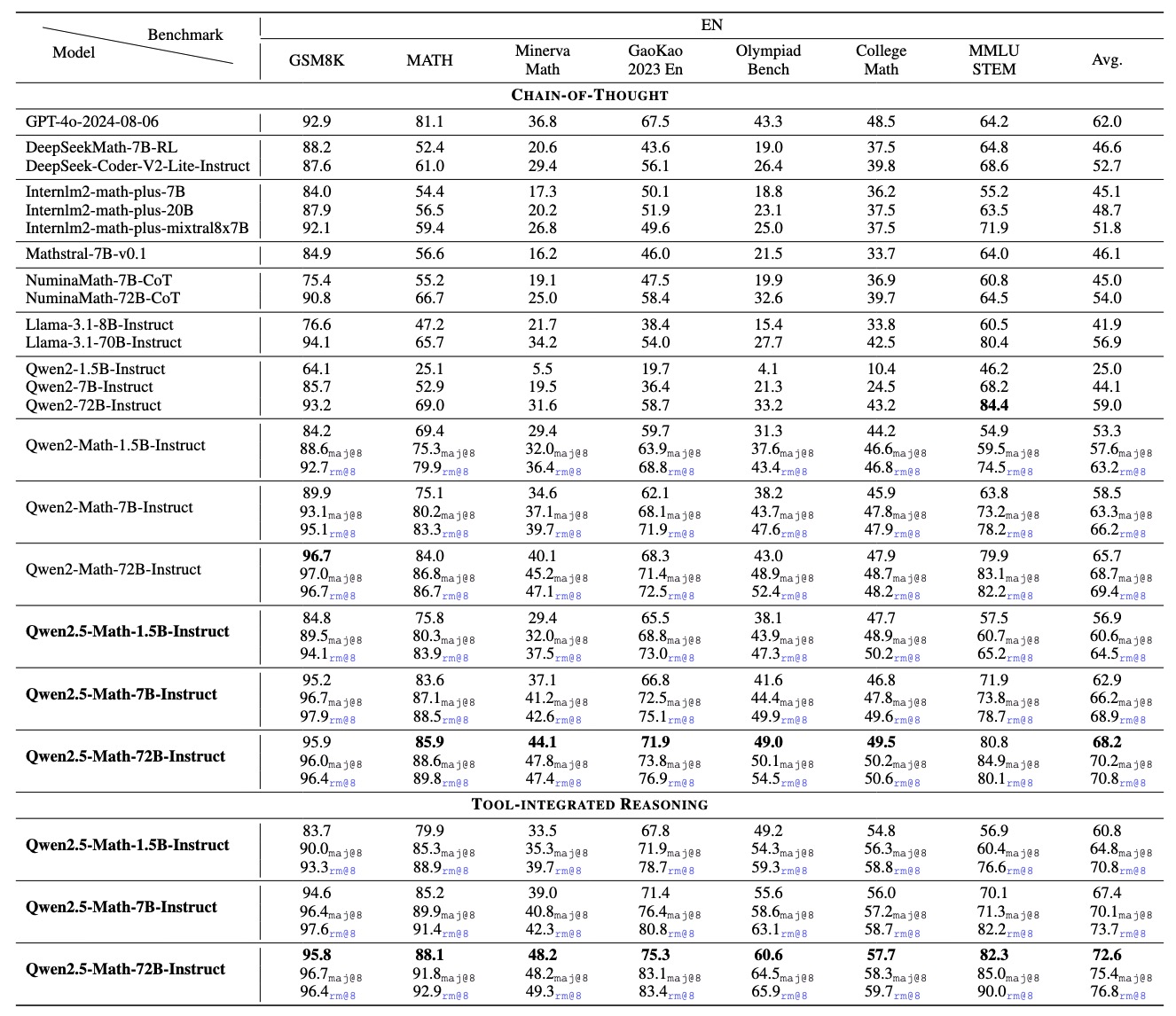
Three sizes, one goal: solve math problems better than anything else at comparable scale. The jump from Qwen2-Math to Qwen2.5-Math was massive — the 7B went from a MATH score in the low 50s to 83.6 with Chain-of-Thought and 85.3 with TIR. For context, the previous-generation Qwen2-Math-72B scored 51.1 on the same benchmark. The new 7B model, at one-tenth the size, blows it away.
| Model | Params | MATH (CoT) | MATH (TIR) | GSM8K | License |
|---|---|---|---|---|---|
| Qwen2.5-Math-1.5B-Instruct | 1.5B | ~75.0 | ~80.0 | — | Apache 2.0 |
| Qwen2.5-Math-7B-Instruct | 7B | 83.6 | 85.3 | 91.6 | Apache 2.0 |
| Qwen2.5-Math-72B-Instruct | 72B | ~88.0 | 92.9 (RM@8) | — | Apache 2.0 |
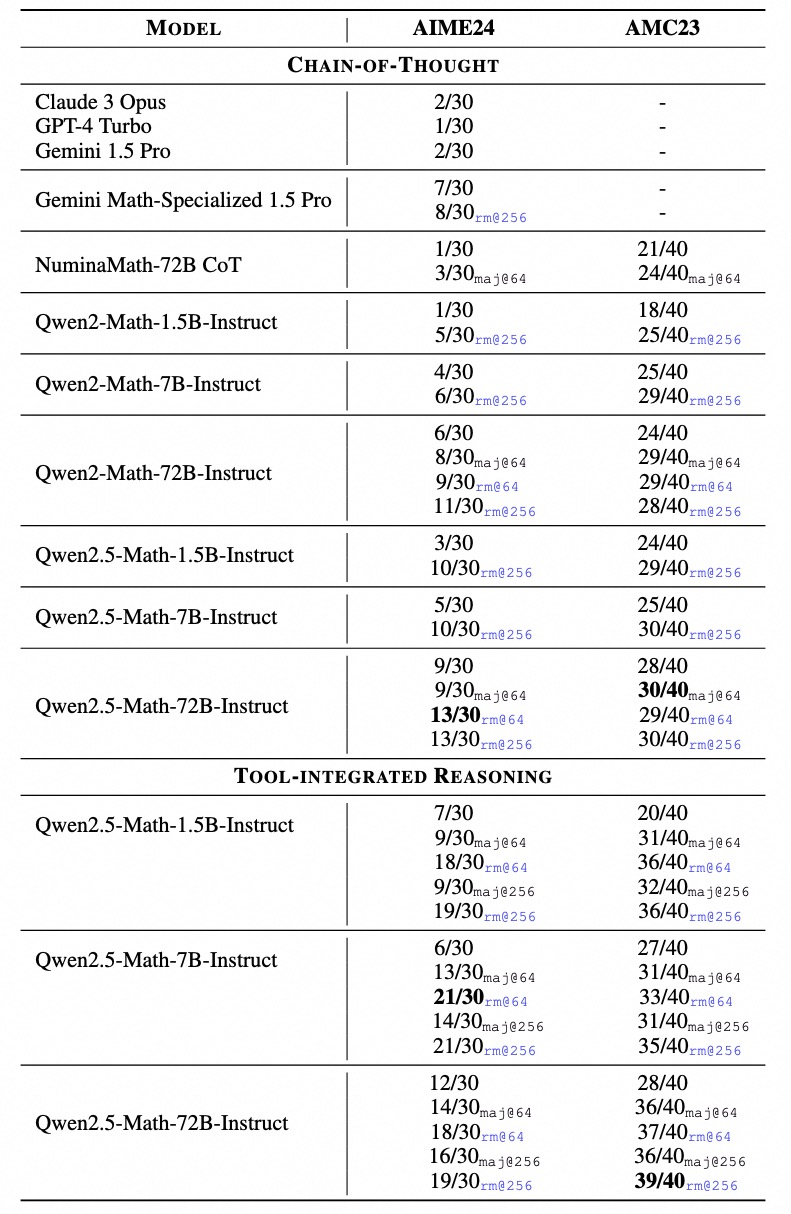
The standout number: the 72B hits 92.9 on MATH with TIR and RM@8 sampling — that's near-human performance on a benchmark once considered a serious challenge for AI systems. And the 72B can solve almost all AMC 2023 problems, putting it in competition-level territory.
But here's the number that turns heads. Compare the 7B against models 50x its size:
| Model | Size | MATH Score |
|---|---|---|
| Qwen2.5-Math-7B | 7B | 83.6 |
| Qwen2-Math-72B | 72B | 51.1 |
| Llama-3.1-405B | 405B | 53.8 |
A 7-billion parameter model scoring 83.6 while Llama-3.1-405B manages 53.8. That's a 30-point gap with 1/58th of the parameters. It's the clearest proof that domain-specific training can overcome raw scale — at least in a well-defined domain like mathematics.
A caveat worth noting: these are math-only benchmarks. Qwen2.5-Math models are narrow specialists. Ask them to write an email, summarize an article, or generate code that isn't math-related, and they'll struggle. That's by design — but it means you shouldn't treat these as general-purpose assistants. For that, look at Qwen 3 or Qwen 3.5.
Tool-Integrated Reasoning: Math with a Python Interpreter
This is the feature that separates Qwen2.5-Math from every other math-focused LLM. Tool-Integrated Reasoning (TIR) means the model doesn't just think through problems step-by-step — it writes Python code, executes it in a sandboxed interpreter, reads the output, and uses that output to continue reasoning. It's Chain-of-Thought with a calculator built in.
Why does this matter? Because LLMs are terrible at arithmetic. They can set up equations perfectly and then miscalculate 47 x 83. TIR solves this by offloading computation to Python. The model handles the reasoning; Python handles the numbers. Think of it as giving the model a scratch pad that actually computes — and that's a massive advantage on multi-step problems where one arithmetic error cascades through the entire solution.
Other math models rely on Chain-of-Thought alone, essentially asking the LLM to be both the mathematician and the calculator. Qwen2.5-Math splits those roles. The practical difference shows up most on problems involving large numbers, nested calculations, or symbolic algebra — exactly the kinds of problems that trip up pure CoT approaches.
How TIR Works in Practice
When you send a math problem to Qwen2.5-Math-Instruct with TIR enabled, the model follows a loop:
- Analyze the problem — break it into sub-problems using natural language reasoning
- Generate Python code — write a snippet to solve the current sub-problem (using sympy, numpy, or plain arithmetic)
- Execute and read output — the Python interpreter runs the code and returns results
- Continue or conclude — use the computed result to move to the next step, or produce the final answer
The impact on accuracy is measurable. The 7B model jumps from 83.6 (CoT only) to 85.3 with TIR on the MATH benchmark. For the 72B, the gains are even larger — TIR with RM@8 sampling pushes it to 92.9. The harder the problem involves numerical computation, the bigger the TIR advantage.
Running TIR Locally
TIR requires a Python execution environment. The recommended approach is using Qwen-Agent, which provides a built-in math tool. Here's the minimal setup:
pip install qwen-agent
# Use the TIR math assistant
python -m qwen_agent.agents.tir_mathQwen-Agent handles the sandbox, code execution, and multi-turn reasoning loop. If you're building a custom pipeline, you'll need to intercept the model's Python output blocks, run them in a sandboxed interpreter, and feed results back as the next turn. The Qwen-Agent GitHub repo has reference implementations.
When to Use TIR vs Plain CoT
TIR isn't always the right choice. Every code execution round-trip adds latency — typically 1-3 seconds per Python call, depending on your hardware. For a simple "what's 15% of 340?" question, CoT gets there instantly with no overhead. Here's how to think about it:
| Problem Type | Best Mode | Why |
|---|---|---|
| Basic arithmetic, simple algebra | CoT | Fast enough, no execution overhead needed |
| Multi-step word problems | TIR | Multiple calculations that can cascade errors |
| Combinatorics, probability | TIR | Factorial/binomial calculations are error-prone in CoT |
| Symbolic algebra (solve, simplify) | TIR | SymPy handles symbolic manipulation perfectly |
| Geometry proofs | CoT | Reasoning-heavy, minimal computation |
| Competition problems (AMC, AIME) | TIR | Complex multi-step with numerical verification needed |
Heads up: if you're building an application, consider letting users toggle between modes. Some problems benefit from TIR's precision; others just need a quick CoT answer. The Qwen-Agent framework supports both modes with the same model weights.
How Qwen2.5-Math Was Trained
The training pipeline explains why such a small model can beat giants. It's a four-stage process that squeezes maximum mathematical ability out of every parameter:
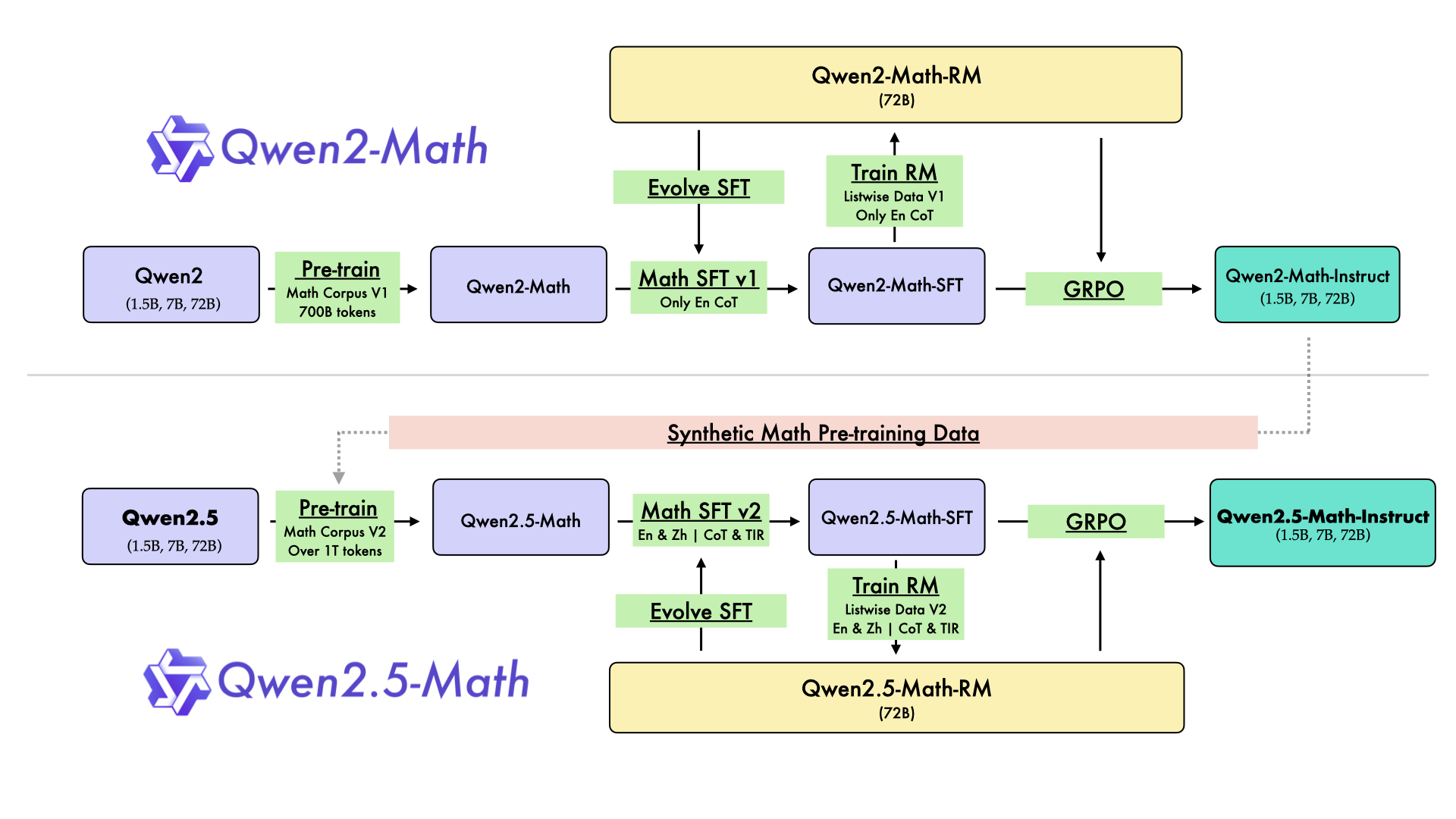
Stage 1: Large-Scale Math Pre-training
Starting from the Qwen2.5 base model, the team continued pre-training on a massive math-specific corpus: textbooks, academic papers, competition archives, web-scraped math content, and synthetic problem-solution pairs. This is the stage where the model internalizes mathematical patterns, notation, and reasoning structures. The corpus is bilingual — English and Chinese — which is why these models handle math problems in both languages.
Stage 2: Math-Specific Instruction Tuning (SFT)
Supervised fine-tuning on curated math Q&A pairs. Both CoT-format answers (step-by-step natural language) and TIR-format answers (reasoning + Python code) are included, so the instruct model learns both reasoning styles. The quality of this data matters enormously — poorly formatted or incorrect solutions would teach the model bad habits.
Stage 3: Reward Model Training
Here's where it gets clever. The team trained a dedicated Qwen2.5-Math-RM-72B reward model that scores mathematical solutions on correctness and reasoning quality. This 72B reward model is then used to rank outputs from the smaller models during the final training stage.
Stage 4: Self-Improvement via GRPO
Using Group Relative Policy Optimization (GRPO), the models generate multiple candidate solutions for each problem. The reward model scores them, and the policy is updated to favor higher-scoring approaches. This iterative self-improvement loop is why the final instruct models significantly outperform their SFT-only versions. It's also why the RM@8 scores (best-of-8 samples ranked by the reward model) are substantially higher than greedy decoding scores.
This pipeline isn't unique to Qwen — it borrows from established techniques. But the execution is unusually thorough: a dedicated 72B reward model, bilingual data at every stage, and separate training tracks for CoT and TIR modes. The separate reward model is probably the single most important ingredient — without it, the GRPO self-improvement stage wouldn't have a reliable signal to optimize against, and you'd end up with a model that's fluent at generating solutions but not necessarily correct ones.
An honest caveat on benchmarks: the RM@8 scores (like the 72B's 92.9 on MATH) represent best-of-8 sampling scored by the reward model. That's not what you get from a single greedy decode. In real-world use, you'll see lower scores unless you implement the same sampling-and-ranking approach. Greedy decoding is significantly worse. If you're building a production system, consider running multiple samples and using the reward model to pick the best one — that's how you get closer to the published numbers.
Qwen3 vs Qwen2.5-Math: Which One for Math?
Qwen3 (released April 2025) doesn't have a separate "-Math" variant. Instead, mathematical capability is integrated into the general-purpose models. And the numbers are strong: Qwen3-235B scores 85.7 on AIME 2024, well above what Qwen2.5-Math-72B achieves on the same benchmark.
So why would anyone still use Qwen2.5-Math? Three reasons:
| Factor | Qwen2.5-Math | Qwen3 |
|---|---|---|
| TIR (Python execution) | Built-in, optimized | Not specialized for TIR |
| Size efficiency | 7B runs on 8GB VRAM | Smallest capable: 32B+ |
| Math focus | 100% math specialist | General-purpose with strong math |
| Best for | Math tutoring, computation, education | Multi-task workflows with math mixed in |
| AIME-level problems | 72B needed; decent but not top-tier | 235B: 85.7 AIME'24 (top-tier) |
Our recommendation: if math is your entire use case — building a tutoring app, an equation solver, a homework checker — and you need it lightweight, Qwen2.5-Math-7B with TIR is hard to beat. It's small, fast, specialized, and the TIR pipeline gives it a practical edge that general models lack.
If math is part of a broader workflow (coding assistant that handles equations, a research agent that reasons quantitatively), go with Qwen3. You get competitive math performance plus everything else. The tradeoff is size: Qwen3's math-capable models are much larger and can't run on consumer hardware as easily. Check our hardware compatibility tool to see what fits your setup.
There's an interesting historical connection here too. Qwen3's training used synthetic math data generated by Qwen2.5-Math models. So in a sense, the math specialist helped train its general-purpose successor. But Qwen3 doesn't have the dedicated TIR pipeline — its math capability comes from reasoning tokens (the "thinking" mode) rather than code execution. Different approach, different strengths.
For competition-level math specifically, the gap is clear. Qwen3-235B hits 85.7 on AIME 2024, which is substantially higher than what Qwen2.5-Math-72B achieves on the same problems. But if you're not solving competition problems — if you're building a calculator app, a tutoring chatbot, or an equation checker — the 7B with TIR gives you 95% of the practical value at a fraction of the compute cost.
Running Qwen2.5-Math Locally and via API
Hardware Requirements
| Model | FP16 VRAM | Q4 VRAM | Fits on |
|---|---|---|---|
| 1.5B | ~3 GB | ~1.5 GB | Any modern GPU, even integrated |
| 7B | ~14 GB | ~5 GB | RTX 3060 12GB, RTX 4060 Ti, M1 Pro+ |
| 72B | ~144 GB | ~40 GB | Multi-GPU (2x A100) or M2 Ultra 192GB |
The 7B at Q4 is the sweet spot for most users. It fits comfortably on an 8GB GPU, leaves room for context, and retains strong benchmark performance even after quantization. If you're running it for a tutoring app or education tool, this is the model to start with.
One thing to watch: the models use a 4K token context window by default. That's plenty for individual math problems but won't work for long documents or multi-page exam sheets in a single prompt. If you need longer context, you can extend it during inference, but expect some quality degradation beyond 4K — the models weren't trained on longer sequences.
Local Deployment with HuggingFace Transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-Math-7B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
prompt = "Solve for x: 3x^2 + 7x - 6 = 0"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=512)
print(tokenizer.decode(output[0], skip_special_tokens=True))Requires Transformers 4.40.0+. For TIR mode, you'll need to use Qwen-Agent or implement your own code execution loop — plain Transformers inference only gives you CoT mode.
Running via Ollama
Community-maintained Ollama models exist for Qwen2.5-Math. The quickest way to get started:
ollama run qwen2.5-math:7bNote that Ollama runs CoT-only inference. There's no built-in TIR support in Ollama, so you won't get the Python execution loop. For TIR, stick with Qwen-Agent or a custom pipeline. If you want to explore more local deployment options, see our full guide on running Qwen locally.
API Access via DashScope
Alibaba offers two API models for Qwen Math through DashScope:
- qwen-math-plus — higher quality, based on the 72B
- qwen-math-turbo — faster, lower cost, based on smaller models
Both support TIR mode via the API. If you don't want to manage infrastructure and need math reasoning in production, the API is the easiest path. Pricing is available on our API overview page.
Frequently Asked Questions
Should I use Qwen2.5-Math or Qwen3 for math?
Depends on your setup. If math is your only task and you want a lightweight, efficient model with TIR support, Qwen2.5-Math-7B is the better pick. If you need a general-purpose model that also handles math well (alongside coding, writing, reasoning), Qwen3 is the way to go — but you'll need significantly more hardware.
Which size should I pick?
7B is the sweet spot for most users. It's the model that beats Llama-3.1-405B on MATH, runs on a single consumer GPU, and supports both CoT and TIR. Go with 1.5B only for extremely constrained environments (mobile, edge). Go with 72B if you're tackling competition-level math or need the highest possible accuracy and have multi-GPU hardware.
Does Qwen2.5-Math work for proofs and formal reasoning?
It handles informal proof-style reasoning through Chain-of-Thought reasonably well — you'll get step-by-step derivations. But it's not trained for formal proof languages (Lean, Coq, Isabelle). For computational problems — solving equations, calculating probabilities, numerical optimization — TIR mode is where this model truly shines.
Is Qwen2.5-Math bilingual?
Yes. Both English and Chinese are supported at training level. You can input math problems in either language and get coherent solutions. English performance is slightly stronger on most benchmarks, but Chinese support is solid — it's trained on Chinese math corpora including GaoKao and CMATH datasets.
What happened to Qwen2-Math?
Qwen2-Math (July 2024) was the first generation, covering 1.5B, 7B, and 72B sizes. Qwen2.5-Math replaced it entirely in September 2024 with dramatically better scores — the 7B's MATH score jumped from the low 50s to 83.6. There's no reason to use Qwen2-Math anymore. If you're running it, switch to 2.5.