
Qwen3-Coder-Next: Alibaba's 80B Open-Source Coding Agent
Qwen3-Coder-Next is Alibaba Cloud's newest code-focused AI model, launched on February 3, 2026. Built on a Mixture-of-Experts (MoE) architecture with 80 billion total parameters but only 3 billion active during inference, it delivers frontier-level coding performance at a fraction of the compute cost. The model supports a massive 256K token context window, native tool calling, and agentic workflows — making it one of the most efficient open-source coding models available today under the Apache 2.0 license.
What makes Qwen3-Coder-Next stand out isn't just raw intelligence — it's how that intelligence is delivered. With only 3B parameters active per token (out of 512 experts), inference speeds reach 60–70 tokens per second on consumer hardware. Early testers have reported running six simultaneous inference windows at a combined 150 tokens/second using batch processing. This model isn't designed to just autocomplete your code — it's trained to autonomously debug, test, and fix real-world software. For the broader Qwen ecosystem, check the Qwen 3 family overview.
In This Guide
Key Specifications
| Developer | Alibaba Cloud — Qwen Team |
| Release Date | February 3, 2026 |
| Total Parameters | 80 billion (79B non-embedding) |
| Active Parameters | 3 billion per token |
| Architecture | Hybrid MoE — Gated DeltaNet + Gated Attention |
| Total Experts | 512 (10 active + 1 shared per token) |
| Context Length | 262,144 tokens (256K native), up to ~1M with YaRN |
| Layers | 48 (hybrid layout) |
| Hidden Dimension | 2,048 |
| License | Apache 2.0 (fully open, commercial use allowed) |
| Thinking Mode | Non-thinking only (no <think> blocks) |
| Key Strengths | Agentic coding, tool calling, error recovery, long-horizon reasoning |
Architecture: Hybrid MoE with Gated DeltaNet
Qwen3-Coder-Next introduces a novel hybrid architecture that sets it apart from traditional transformer-based coding models. Each of its 48 layers follows a repeating pattern: 12 × (3 × Gated DeltaNet → MoE + 1 × Gated Attention → MoE). This design combines two complementary attention mechanisms:
- Gated DeltaNet — A linear attention variant with 32 value heads and 16 query/key heads (128-dim each). This mechanism is specifically optimized for long-horizon reasoning and efficient context handling, allowing the model to process massive codebases without the quadratic memory cost of full attention.
- Gated Attention — Traditional multi-head attention with 16 query heads, 2 key/value heads, and 256-dim heads plus 64-dim rotary position embeddings. This handles tasks that require precise token-level attention patterns.
The MoE layer routes each token to 10 out of 512 available experts (plus 1 shared expert), each with a compact 512-dimensional intermediate size. This extreme sparsity is what allows the model to have 80B total parameters while only activating 3B — achieving what researchers call the "Pareto frontier" of efficiency: maximum intelligence at minimum compute cost.
A critical practical benefit: the hybrid attention design means context length can scale to 256K tokens without the massive VRAM ballooning typically seen with standard self-attention models. Early testers have confirmed that running at 65K context on quantized versions keeps memory usage well within consumer hardware limits.
From Assistant to Agent: The Paradigm Shift
Previous coding models were essentially sophisticated autocomplete engines — they predicted the next token based on training patterns. Qwen3-Coder-Next represents a fundamental shift from code assistance to code agency.
The model was trained with what Alibaba calls "agentic training signals" across over 800,000 verifiable tasks. Instead of learning from static code examples, it was trained in a simulator-like environment where it could write code, execute it, observe failures, and iteratively correct until the tests pass — all without human intervention.
In practice, this means Qwen3-Coder-Next can:
Community testers have demonstrated the model taking a real bug from an open-source repository, identifying edge-case validation failures, writing a unit test, fixing the code, and verifying the solution — all in approximately 45 seconds.
Benchmarks & Performance
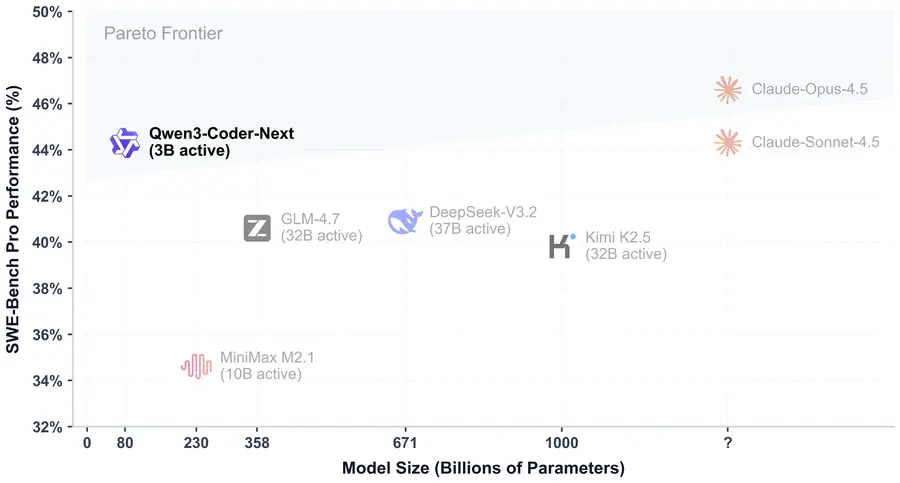
Qwen3-Coder-Next positions itself on the Pareto frontier of coding model efficiency — delivering near-frontier performance at a fraction of the compute cost of larger models.
| Benchmark | Qwen3-Coder-Next | Key Comparison |
|---|---|---|
| SWE-Bench (Coding Agents) | 70.5% | Outperforms DeepSeek V2.5, GLM 4.7 |
| SWE-Bench Pro | 44% | Near Claude Sonnet with 3B active params |
| Active Parameters | 3B | 10–20× more efficient than comparable models |
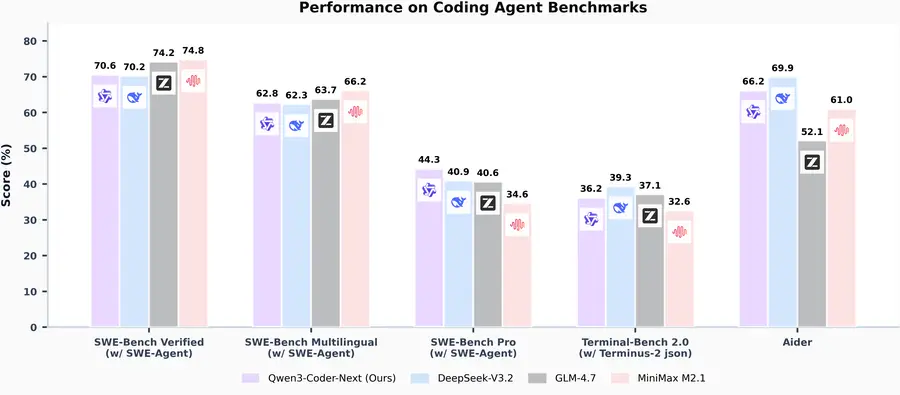
On SWE-Bench, the standard benchmark for autonomous software engineering, the model achieves 70.5% accuracy — navigating large repositories, identifying bugs, and generating fixes autonomously. This surpasses models like DeepSeek V2.5 and GLM 4.7, and sits close to Claude Sonnet on specific coding tasks, although Claude Opus 4.5 still leads overall. The key differentiator is efficiency: Qwen3-Coder-Next achieves these scores with dramatically fewer active parameters than any competitor in its performance tier.
Available Variants on Hugging Face
The model is available in four official variants, all released under Apache 2.0:
| Variant | Description | Best For |
|---|---|---|
| Qwen3-Coder-Next | Full BF16 instruct model (safetensors) | Multi-GPU server deployment with SGLang/vLLM |
| Qwen3-Coder-Next-FP8 | FP8 quantized (block size 128) | Reduced VRAM with near-lossless quality |
| Qwen3-Coder-Next-Base | Pre-trained base model (no instruction tuning) | Fine-tuning and custom training pipelines |
| Qwen3-Coder-Next-GGUF | Quantized GGUF formats (Q4 through Q8) | Local inference with llama.cpp, LM Studio, Ollama |
GGUF Quantization Options
The GGUF variant is the most popular choice for local deployment. Available quantization levels:
| Quantization | Size | Notes |
|---|---|---|
| Q4_K_M (4-bit) | ~48 GB | Minimum viable — needs 45+ GB combined RAM |
| Q5_K_M (5-bit) | ~57 GB | Good balance — 95% token accuracy, fits 64 GB systems |
| Q6_K (6-bit) | ~66 GB | Higher quality |
| Q8_0 (8-bit) | ~85 GB | Near-lossless — requires 128 GB systems |
| Q9 (9-bit) | ~83 GB | Near-lossless compression, best quality-to-size ratio |
How to Run Qwen3-Coder-Next Locally
There are multiple ways to run this model on your own hardware. Below are the most popular options.
Option 1: llama.cpp (Recommended for GGUF)
The most common approach for local inference with quantized GGUF files.
- Download the GGUF model:
huggingface-cli download Qwen/Qwen3-Coder-Next-GGUF --include "Qwen3-Coder-Next-Q5_K_M/*" - Run with llama.cpp:
./llama-cli -m ./Qwen3-Coder-Next-Q5_K_M/Qwen3-Coder-Next-00001-of-00004.gguf --jinja -ngl 99 -fa on -sm row --temp 1.0 --top-k 40 --top-p 0.95 --min-p 0 -c 40960 -n 32768 --no-context-shift
Option 2: Ollama
The easiest option for getting started quickly.
- Install Ollama from ollama.com (Windows, macOS, Linux).
- Pull and run the model:
ollama run qwen3-coder-next
Option 3: LM Studio
A GUI-based option for users who prefer a visual interface.
- Download LM Studio.
- Search for
Qwen3-Coder-Nextin the model browser. - Select your preferred quantization (Q5 for 64 GB systems, Q8 for 128 GB+).
- Set recommended sampling:
temperature=1.0,top_p=0.95,top_k=40.
Option 4: vLLM / SGLang (Server Deployment)
For production-grade or multi-GPU deployments with OpenAI-compatible API endpoints.
vllm serve Qwen/Qwen3-Coder-Next --port 8000 --tensor-parallel-size 2 --enable-auto-tool-choice --tool-call-parser qwen3_coderpython -m sglang.launch_server --model Qwen/Qwen3-Coder-Next --port 30000 --tp-size 2 --tool-call-parser qwen3_coderBoth expose OpenAI-compatible endpoints at their respective ports with full tool calling support.
Recommended Sampling Parameters
Regardless of the deployment method, the Qwen team recommends these settings for best results:
| Parameter | Value |
|---|---|
| Temperature | 1.0 |
| Top P | 0.95 |
| Top K | 40 |
| Max New Tokens | 65,536 |
Hardware Requirements
Thanks to the MoE architecture, Qwen3-Coder-Next is far more accessible than its 80B total parameter count would suggest. The key requirement is combined system memory (RAM + VRAM), not just GPU memory alone.
| Setup | Quantization | Memory Needed | Expected Speed |
|---|---|---|---|
| Consumer PC (64 GB RAM) | Q5_K_M (5-bit) | ~57 GB combined | ~60–70 t/s |
| High-end workstation (128 GB RAM) | Q8/Q9 (8-9 bit) | ~83–85 GB combined | ~60+ t/s |
| GPU server (H100 80 GB) | Full / FP8 | ~48–80 GB VRAM | Very fast |
| Multi-GPU (2× A100/H100) | BF16 full precision | Distributed | Production-grade |
Important: The hybrid attention architecture means context length scales without the typical VRAM explosion. A 4-bit quantization at 65K context has been confirmed to run within consumer-level memory budgets. If you encounter out-of-memory issues, reducing context to 32K is a quick fix. For extended context up to ~1M tokens, YaRN rope scaling is supported in llama.cpp.
You don't need to own a high-end GPU — cloud GPU rental services offer H100 instances by the hour at reasonable cost. For a deeper dive into running Qwen models on your own hardware, see our guide to running Qwen locally and our hardware requirements page.
Real-World Field Tests
Independent testers have put Qwen3-Coder-Next through extensive practical evaluations. Here's what stood out from community testing:
Software Development & Web Design
- Browser-based OS — Generated a fully functional MacOS-style operating system in the browser, complete with working calculator, image gallery, wallpaper customization, and a real-time audio visualizer using the Web Audio API. Testers called it one of the most feature-complete single-shot HTML generations they'd seen.
- EV Startup Landing Page — Created a modern responsive page with working animated counters, charts without visual deformations, glassmorphism cards, interactive tabs, and creative copywriting — all in a single HTML file. Reviewers described it as competitive with outputs from leading proprietary models.
- SQL Optimization — Correctly identified three major performance issues (non-sargable predicates, correlated subqueries) and provided two solid optimization approaches with indexing recommendations. Described as production-quality advice by experienced database engineers.
Games & Simulations
- Minecraft (Voxel World) — Generated what testers called the best AI-made Minecraft clone, with real-time voxel editing functionality.
- 3D Racing Game — Produced a highway racing game with vehicle physics (lean on turns), collision effects, multiple car models, and smooth death transitions. Rated better than equivalents produced by Claude in similar tests.
- 3D Printer Simulation — After one iteration to fix a browser compatibility issue, delivered a working simulation with layer-by-layer building, nozzle color changes when heated, and a movable gantry.
Iterative Improvement
A consistent finding across all tests: the model excels at iteratively fixing its own code. When given error output from a browser console or test runner, it could identify the problem and produce a corrected version — often dramatically improving the result on the second or third attempt. This aligns with its agentic training methodology.
Agentic Capabilities & IDE Integration
Qwen3-Coder-Next is specifically designed for agentic coding workflows — not just answering questions about code, but actively operating within development environments.
Supported Coding Environments
The model integrates with major IDE-based coding agents:
- OpenCode / Open Claw — Functions as a local alternative to cloud-based coding assistants, processing the system prompt and responding to agentic tasks at high speed.
- Claude Code, Qwen Code, Cline, Kilo, Trae, Qoder — Compatible with scaffolds from multiple AI coding platforms.
- Browser automation — Can operate web browsers, search for products, interact with web applications, and automate desktop tasks.
Tool Calling
Native tool calling is a first-class feature. The model can invoke external tools through structured function calls, enabling workflows like: reading files → running tests → analyzing output → applying fixes. Both vLLM and SGLang support the dedicated qwen3_coder tool-call parser for seamless integration.
Official Video Demo
The Qwen team published a demo video on YouTube showcasing the model's agentic capabilities — including desktop cleanup, web page creation, browser automation, and chat interface generation.
Limitations & Considerations
Despite its impressive capabilities, Qwen3-Coder-Next has some notable limitations to be aware of:
- No thinking mode — Unlike models with explicit chain-of-thought (CoT), this model operates in non-thinking mode only. While this boosts speed, it means less transparency in complex reasoning steps.
- Hit-or-miss on complex single-shot tasks — Ambitious tasks like flight combat simulators or full Photoshop clones have proven unreliable in one-shot generation. The model often needs iterative refinement for complex projects.
- Tool calling learning curve — Some testers reported that the model occasionally struggles with multi-step tool-calling chains, particularly web browsing tools, where it may need manual guidance or broken-down instructions.
- Quantization trade-offs — While 4-bit quants are usable, testers observed that 5-bit (Q5) offers 95% token accuracy and is the sweet spot for most users. Going below Q4 may noticeably degrade quality.
- Website design variety — When generating multiple websites in sequence, outputs tend toward similar minimalist layouts. Detailed design prompts help mitigate this.
Final Verdict
Qwen3-Coder-Next represents a significant milestone in open-source coding AI. By achieving near-frontier performance with only 3 billion active parameters, it democratizes access to powerful autonomous coding agents — something previously locked behind expensive API calls or massive GPU clusters.
Its strengths are clear: exceptional speed, efficient memory usage, strong agentic capabilities, and impressive iterative self-correction. The Apache 2.0 license makes it viable for commercial use, and the diverse deployment options (llama.cpp, Ollama, LM Studio, vLLM, SGLang) mean there's an entry point for virtually any setup.
For developers exploring local AI coding agents, this is currently one of the most compelling options available. It won't replace frontier models like Claude Opus for the most complex tasks, but for the vast majority of coding workflows — especially agentic, iterative ones — it delivers outstanding value.
Looking for more Qwen models? Explore the full Qwen 3 family, try Qwen AI Chat, or check our guide to running Qwen models locally.